昨年(1998年)12月17〜19日に、早稲田大学国際会議場と理工学部で、「マルチリンガルテキスト処理国際シンポジュウム」が開かれた(主催早稲田大学、協賛情報処理学会)。チベット語、雲南少数民族諸語、ウイグル語、タイ語、ラオスのラオ語の文字コードの国家規格に関与している政府機関の研究者が来日し、日本側からは大谷大と早稲田大の研究者が報告をおこなった。これだけ多彩な顔ぶれが一堂に会したのは、世界的にも例がないという。
ICMTP'98のレポートは別に書いたが、本稿では多言語テキスト処理でなにが問題になるかを、結合音節文字の代表といえるデーヴァナーガリー文字とそれをコード化したインドの国家規格 IS 13194、さらにアラビア文字を借用するウィグル語で説明したい。聞きなれない文字の名前や、なじみのない表記体系がでてくるが、日本語を考える上にも示唆にとむので、しばらくおつきあい願いたい。
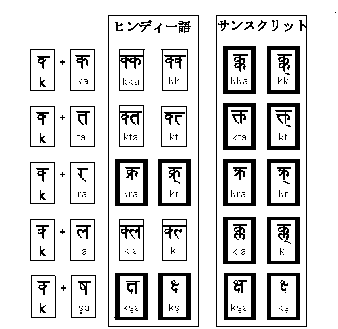
デーヴァナーガリー文字は、古代ブラフミー文字に淵源する表記体系で、部品を組みあわせて一文字を表現する結合音節文字に分類される。サンスクリット、ヒンディー語などで使われており、使用人口は日本語人口よりも多い。インドには他にパンジャブ文字、グジャラート文字、ベンガル文字、タミール文字など、主なものだけで九の表記体系があるが、いずれもブラフミー文字起源であり、デーヴァナーガリー文字と共通の構造をもち、大半の字が一対一対応している。チベット文字、タイ文字、ビルマ文字、ラオスで使われるラオ文字なども、デーヴァナーガリー文字の影響下で生まれた表記体系である。デーヴァナーガリー文字に代表されるインド系文字の使用人口は数億におよび、使用地域も広大である。
デーヴァナーガリー文字にも母音字と子音字の区別があるが、ヨーロッパのアルファベットに親しんできた人間にとって一番面食らうのは、子音字が[a]という母音を潜在させていることだろう。ラテン文字の子音字が純粋な子音をあらわすのに対し、デーヴァーナーガリ文字系の子音字は子音ではじまる音節をあらわすのである。
「川」をあらわす「ナディー」は ![]() とつづるが(横棒で連結された字形のまとまりが一単語である)、
とつづるが(横棒で連結された字形のまとまりが一単語である)、 ![]() だけで「ナ」という音節をあらわす。「ディー」
だけで「ナ」という音節をあらわす。「ディー」![]() は、「ダ」
は、「ダ」![]() と長母音の「イー」
と長母音の「イー」![]() を組みあわせている。
を組みあわせている。
長母音の「イー」は独立した文字としては ![]() と表記するが、子音字と組み合わせる際は
と表記するが、子音字と組み合わせる際は ![]() という字形をとる。前者を母音字、後者を母音記号と呼んで区別する。
という字形をとる。前者を母音字、後者を母音記号と呼んで区別する。
撥音や促音は子音字を重複させることであらわすが、子音字には[a]が含まれているのだから、単に重複させただけでは二音節になり、撥音や促音にならない。[a]をふくまない子音音節をあらわすにはいくつかの表記法があるが、一番わかりやすいのはハラント ![]() という記号(修飾子)を付加する方法である。「ダ」
という記号(修飾子)を付加する方法である。「ダ」![]() の場合、
の場合、 ![]() と表記することで、母音をふくまない子音音節をあらわすことができる。英国植民地時代にデーヴァナーガリー・タイプライタが導入されたが、字母数が限られていたので、半子音字はハラントの重ね打ちで表現した。
と表記することで、母音をふくまない子音音節をあらわすことができる。英国植民地時代にデーヴァナーガリー・タイプライタが導入されたが、字母数が限られていたので、半子音字はハラントの重ね打ちで表現した。
だが、ハラントの重ね打ちはあくまで便方であり、タイプライタ以外では使われないという。子音字には「カ」![]() のように縦軸をもった字が多いが、その場合、右半分を取りさって
のように縦軸をもった字が多いが、その場合、右半分を取りさって ![]() のように字形を替える。これを半子音字と呼ぶ。[kka]と同じ子音を重複させて促音をあらわすには、
のように字形を替える。これを半子音字と呼ぶ。[kka]と同じ子音を重複させて促音をあらわすには、 ![]() のように縦に重ねたり、
のように縦に重ねたり、 ![]() のように横につらねたりする(伝統的には縦方式だが、新聞などでは組版上の制約から、横方式が多い)。
のように横につらねたりする(伝統的には縦方式だが、新聞などでは組版上の制約から、横方式が多い)。
これだけでも十分複雑で、外国人は頭をかかえなければならないが、本当にややこしいのはこれからである。半子音字と子音字の組みあわせは、さまざまなリガチャー(合字)になって、字形が替わるるからだ。
二つの字が合体して、似ても似つかない字形に変化したものをリガチャーと呼ぶ。日本人にはドイツ語の「ß」くらいしか思い浮ばないが、世界の表記体系にはリガチャーを多用するものがすくなくない。デーヴァナーガリー文字もその一つで、「k」![]() と「シャ」
と「シャ」![]() で
で ![]() になり、「d」
になり、「d」![]() と「ヤ」
と「ヤ」![]() で
で ![]() になる。
になる。
デーヴァナーガリー文字はネパール語などでも用いられているほか、タミル文字、パンジャブ文字など、他の公用文字の転写にも使われているが、下の対応表のように、ヒンディー語とその古典語にあたるサンスクリット語ですらリガチャーが異なる。言語が特定できないと表示すらできないのである。
さらに鼻音化するために付加する修飾子二種と、 ![]() のように付加されるヌクタという流音化の修飾子がある。
のように付加されるヌクタという流音化の修飾子がある。
このような複雑怪奇な表記体系(インドから見れば、日本語の表記体系も複雑怪奇だろうが)を、コンピュータ化することが可能なのだろうか?
インドの国家規格であるIS 13194は、日本のJIS X 0201と同じ7bitおよび8bitの文字コードだが、規格中でテキスト処理における文字単位を定義し、外部コードにおける単位、テキスト処理における単位、表示処理における単位を階層化することで、みごとな解決をあたえている。
| mbでの単位 | ||||||||
|---|---|---|---|---|---|---|---|---|
| WCでの単位
テキスト処理の単位 |
||||||||
| 図形での単位 | ||||||||
| 音節での単位 | ||||||||
上図をご覧いただきたい(片岡裕 文献1より引用)。最上層の「mbでの単位」は外部コードにおける単位で、コード表に定義された文字部品がならんでいる(mbはマルチ・バイトの略)。キーボードに刻印されているのもこの文字部品で、入力する際は最上層にならんだ順序で打鍵していく。
先頭の![]() は「カ」で、次の
は「カ」で、次の ![]() は「アー」という母音記号、三番目の
は「アー」という母音記号、三番目の ![]() は鼻音化する修飾子である。第二層の「WCでの単位」はテキスト処理の上での単位であって(WCはワイド・キャラクターの略)、
は鼻音化する修飾子である。第二層の「WCでの単位」はテキスト処理の上での単位であって(WCはワイド・キャラクターの略)、 ![]() と
と ![]() は合体して、「アーン」
は合体して、「アーン」![]() という鼻母音になる。一番下は音節での単位で、「カーン」という音節をあらわす。
という鼻母音になる。一番下は音節での単位で、「カーン」という音節をあらわす。
最上層四番目の ![]() は「ガ」、五番目は母音をとりさるハラントである。二層目ではこの二つが合体して、半子音字
は「ガ」、五番目は母音をとりさるハラントである。二層目ではこの二つが合体して、半子音字 ![]() になる(
になる( ![]() から右半分をとりさった字形)。
から右半分をとりさった字形)。 ![]() は「ラ」、
は「ラ」、 ![]() は「エー」の母音記号で、合体すると
は「エー」の母音記号で、合体すると ![]() になる。純粋子音の
になる。純粋子音の ![]() と
と ![]() が表示階層で合体し、
が表示階層で合体し、 ![]() というリガチャーに替わる。音節としては[gre]である。
というリガチャーに替わる。音節としては[gre]である。
一番最後の ![]() は「サ」で、そのまま一音節となる。
は「サ」で、そのまま一音節となる。
IS 13194は94文字のコードであり、母音修飾子、母音字、子音字、母音記号、修飾子、インド数字という順で文字を配列しているが、これはソートを考慮した配置だそうである。また、入力を補助するための非表示操作子と、他の表記体系用の表示機構(リガチャー化する組みあわせは、表記体系によって異なる)に切り替えるための操作子が用意されている点も目を引く。インドには、デーヴァナーガリー文字をはじめとして、パンジャブ文字、グジャラート文字、ベンガル文字、タミール文字など、主なものだけで10の表記体系があるが、IS 13194では、デーヴァナーガリー文字のマッピングに対応させて、各表記体系のマッピングをおこなっている。そのため、表示階層を切り替えることで、フォント切替によって書体を変えるように、10の表記体系を一つの処理系でカバーすることができるのである。
なぜテキスト処理単位という階層を設ければならないのだろうか。なじみのない表記体系の話がつづいたので、少々乱暴だが、日本語に引きつけて説明しよう。
JIS X 0201のGR領域にはカタカナ(いわゆる半角仮名)がマッピングしてある。JIS X 0201は、一見、固定長コードのように見えるかもしれないが、濁点・半濁点が独立したコードに割り当てられているので、「ダ」や「パ」を表記する場合、「タ」+「゙」→「ダ」、「ハ」+「゚」→「パ」としなければならない。つまり、IS 13194やユニコード同様、不定長コードである。
表示するだけなら、「ダ」「パ」でも差し支えないものの、挿入・削除・上書き・検索・置換・ソートといったテキスト処理をする段になると、とたんに問題にぶつかる。
テキスト処理上は「ダ」ないし「パ」で一文字だということがコンピュータにはわからないので、「タ」と「゙」の間に行の折り返しがはいったり、「パ」の「゚」だけをうっかり削除して「ハ」になったりしかねない。「モシ」→「モシモ」という置換をおこなうと、「モジ」が「モシモ゙」になる。ソートも困難である。
仮名文字には濁点・半濁点しかないので、この程度ですんでいるが、文字合成を広範におこなうデーヴァナーガリー文字では目茶苦茶になる。そこで、IS 13194ではテキスト処理上の単位を規格中で定義しているのである(タイ文字ではもっと困ったことになるのだが、今回はふれない)。
漢字を部品の組みあわせによって表現しようという研究をしているグループがあるそうだが、どういう組みあわせの場合に一文字となるかが厳密に定義できない限り、同じ困難に直面する。もし、万一、定義できたとしても、編集上は生成された文字を一単位としてあつかわなければならない以上、コードポイントの節約にはならない。記憶媒体はこれからもどんどん廉価になっていくのだから、漢字の完成形を別々にマッピングした方が、結局は安定で安あがりだろう。
現時点では、結合文字をあつかわない実装レベル1のユニコードしか実装されていないらしいので、問題は表面化していないようだが、デーヴァナーガリー文字をはじめとする結合音節文字をユニコードでテキスト処理するのはきわめて困難だと予想される。
ユニコードでは、IS 13194に規定されているインドの10の表記体系は、A領域のU+0900からU+0D7Fまでに収録されている。デーヴァナーガリー文字の文字部品は U+0900から U+097Fまでにマッピングされており、母音修飾子、母音字、子音字、母音記号、修飾子、数字という順序は踏襲されている。しかし、非表示修飾子と他の表記体系に切り替える属性子がない代りに、ヌクタつき子音字など、あらかじめ合成された15文字が数字の前に割りこんでいるなど、変更点もある。なぜかヌクタの相対コード位置も動いている。
表記体系間の対応関係はほぼ維持されており、デーヴァナーガリー文字のコードポイントに80hの倍数を加えることによって、他の表記体系の対応字のコードポイントを算出することができる。独立のコードポイントをあたえられた ![]() のようなヌクタつき子音字は、デーヴァナーガリー文字とパンジャブ文字でしか使われないので、他の表記体系の対応コードポイントは空所になっている(ヌクタつき子音字は、辞書順ソートでは、つかない子音字と同様にあつかわれるから、独立のコードポイントをあたえるとソートが難しくなると思われる)。
のようなヌクタつき子音字は、デーヴァナーガリー文字とパンジャブ文字でしか使われないので、他の表記体系の対応コードポイントは空所になっている(ヌクタつき子音字は、辞書順ソートでは、つかない子音字と同様にあつかわれるから、独立のコードポイントをあたえるとソートが難しくなると思われる)。
ユニコードは IS 13194の外部コードの層をコピーしたようなものである。ユニコードはもともと内部コードとして開発された。内部コードとして使うことで、プログラムが簡単になるなどのメリットがあるといわれているが、デーヴァナーガリー系の表記体系をテキスト処理しようとすると、テキスト処理上の文字ではなく、文字部品を対象にすることになり、先に述べたような混乱にみまわれる。世界中の文字の字形カタログを作っただけでは、文字コードとして機能しないのである。
シンポジュウムでは、大谷大の箕浦暁雄氏が、右に述べたような IS 13194の構造を解説し、同じデーヴァナーガリー文字を使っていても、ヒンディー語とサンスクリット語では単語末尾の音価が異なるため、サンスクリット語では音節数が増えてしまうこと、したがって発音上の音価を基準にしては文字の単位が決まらないという問題点を指摘した。IS13194がテキスト処理単位を定義しているのは、そのためもあるのだ。
中国社会科学院の江荻氏はチベット語とチベット文字で表記する諸言語について発表した。チベット文字も部品を組み合わせる典型的な結合音節文字であるが、組み合わせの限界が分からないと、文字処理の一単位を定義するルールが制定できない。江氏はチベット文字を使用する諸言語を広範にフィールドワークしており、データの積み重ねを踏まえて音韻構造と表記の関係を論じた。
大谷大の宮下晴輝氏は、大谷大で開発したマッキントッシュのチベット文字システムを紹介しながら、チベット文字の構造と文字コードの決定方法を解説した。字形が同じで音価が異なる文字があること、マッキントッシュのOS構造の問題から実装する上で困難があることを実例をまじえて語った。表示は美しかったものの、テキストを自由に編集できるところまではいっていないらしい。
チベット文字の音写には、文字名方式と発音方式の二種類あるそうだが、発音されない文字があり、言語学でよく使用される発音方式では、文字の字形情報がまったく欠落してしまう。また、ツェックという記号は、区切り記号ということになっているが、実は区切り記号として使えないケースもあることが紹介された。ユニコードにはチベット文字の部品が追補されたが、音価の異なる文字が同一文字となってしまい、区別できなくなるという。
タイ国家電子計算機技術センターのスラパント・メクナビン氏はタイ文字をテキスト処理する上での問題点と歴史を解説した。タイの文字コードは国家規格に問題があるために、さまざまな規格が乱立状態にあるそうで、その混乱がはからずもソフト産業の成長を促進した面があるらしい。一文字の真ん中に行の折り返しがはいるケースは日常的に起こっているそうで、こうした事態をさけるためには、目に見えない区切り記号が必要になる。この区切り記号は、タイ国家規格にもユニコードにもない。
ラオス科学技術環境委員会・計算機センター所長のポンパシット・ピッサマイ氏は、ラオ文字の表記体系とコンピュータ処理の問題点を解説した。素人目にはタイの文字とどこが違うのかわからないのであるが、ラオ文字が日本でまとまって紹介されたのは、今回が初めてだそうである。ラオ文字もタイ文字と同じ区切り記号問題をかかえている。
新疆ウイグル自治区言語工作委員会のヤスン・イミン氏は、ウィグル語・中国語などがあつかえる多言語新聞組版システムの開発者で、ウィグル語写植システムの事実上の標準になっている。ウィグル語は膠着語に属するトルコ系言語だが、アラビア文字をもとにした文字で表記する。氏はウイグル語文字コードの改良の研究もしており、アラビア語の表記体系とウイグル語の表記体系の差異をあきらかにした。
アラビア文字はアラビア語のみならず、今あげたウィグル語、さらにはインド=ヨーロッパ語系のペルシャ語など、系統を異にする言語で使われているが、セム語族に属するアラビア語を前提に作られたアラビア文字は、もともと母音を表記しないし、表記する場合も、語中にあらわれる時は子音と合体して、リガチャーとなる。
アラビア語では![]() (l)と
(l)と![]() (a)で
(a)で![]() (la)というリガチャーになるが、ペルシャ語では
(la)というリガチャーになるが、ペルシャ語では![]() (la)のように分離して書く(書字方向は右→左)。ウィグル語ではハムザ
(la)のように分離して書く(書字方向は右→左)。ウィグル語ではハムザ![]() という声門閉鎖をあらわす修飾子を音節の区切りに使い、「ela」にふくまれる「la」を
という声門閉鎖をあらわす修飾子を音節の区切りに使い、「ela」にふくまれる「la」を![]() と表記する。起源と字形が同じだから、言語固有字母をカタログに追加すれば、アラビア文字を使う言語がすべて表記できると思ったら大間違いであって、ウィグル語のような必ず母音をともなう言語では、結合音節文字的性格をおびたまったく別の表記体系となり、既存のアラビア文字コード(いくつもある)やユニコードのような統合方式ではでは使いものにならないという。
と表記する。起源と字形が同じだから、言語固有字母をカタログに追加すれば、アラビア文字を使う言語がすべて表記できると思ったら大間違いであって、ウィグル語のような必ず母音をともなう言語では、結合音節文字的性格をおびたまったく別の表記体系となり、既存のアラビア文字コード(いくつもある)やユニコードのような統合方式ではでは使いものにならないという。
新疆ウイグル自治区では、ウイグル語以外にモンゴル語(トド・モンゴル文字使用)、シボ語(シボ文字使用)など、多数の少数民族が、それぞれの文字で新聞を発行している。こうした新聞の組版には、いずれもヤスン・イミン氏が開発した多言語写植システムが使われている。
雲南省少数民族語文指導委員会の和麗峰氏は雲南少数民族(「少数」といっても、スペインやイタリアくらいの人口がある)の諸言語の文字を紹介し、譚玉![]() 氏は特にダイ文字(正確には、ダイ文字群の中のシーサンパンナー・ダイ文字)にしぼって解説した。ダイ文字は、仏典の翻訳のために作られた千年近い伝統をもつ文字で、国境を越えて使用されているという。彜文字も紹介されたが、同じ名称でまったく異なる文字が四川省でも使用されており、単に言語名や文字名だけでは特定できないので、注意が必要である。
氏は特にダイ文字(正確には、ダイ文字群の中のシーサンパンナー・ダイ文字)にしぼって解説した。ダイ文字は、仏典の翻訳のために作られた千年近い伝統をもつ文字で、国境を越えて使用されているという。彜文字も紹介されたが、同じ名称でまったく異なる文字が四川省でも使用されており、単に言語名や文字名だけでは特定できないので、注意が必要である。
もちろん、こうした文字は新疆同様、日常的に使用されており、各民族ごとに新聞や教科書が発行されている。目下、これらの文字は文字改革が進行しているが、その実情は国外では知ることができないし、民族問題がからんでいるために、現地調査の許可をうるのはひじょうに難しいという。ICMTP'98の運営にあたった早大小原研究室は、これまで中国政府の正式な許可のもとに新疆ウイグル自治区、四川省、雲南省で現地調査をおこなっており、その実績の上に今回の招聘が実現したという。
ヨーロッパ・アルファベット圏で生まれた近代言語学は、文字は音声の不完全な模写にすぎないという音声中心主義を暗黙の前提にしている。音声言語がオリジナルで、文字言語が二次的な模写だとしたら、別の表記体系に変えてもかまわないことになる。だが、言語はそんな単純なものではない。日本語の歴史をちょっとふりかえっただけでも、漢字仮名まじり文という表記体系が、音声言語としての日本語に影響をあたえていることがわかる。今日の日本語は、漢字仮名まじり文と骨がらみになって成立しているのであって、もしカナ表記だけにしてしまったり、ローマ字表記にしてしまったなら、音声言語としての日本語も大きな変容をこうむらざるをえない。ヒンディー語やチベット語、タイ語、ラオ語、ダイ語、彜語などでも、似たような事情があるだろう。
ICMTP'98を通じて確信したのは、文字コード問題は ISO 2022に立ちかえり、各国の文字コードをそのままの形で棲みわけさせるしか、解決の道はないだろうということである。ISO 2022は柔軟な規格であるため、1980年代までの技術では実装しきれなかったようだが、現在の技術なら可能なはずである。情報交換は 7bitないし 8bitで、内部処理は 32bitのワイドキャラクターでおこなえば、ユニコードのような不定長コードよりもすっきりするし、外部コードと内部コードを峻別することで結合音節文字のテキストも処理できる。シンポジュウム最終日にデモがおこなわれた早大小原研究室の System1という多言語編集環境は、こうした考え方で世界中の表記体系を共存させた拡張X Windowシステムだった(現在は片岡裕氏が言語資料の宝庫である大谷大に移ったのにともない、大谷大が開発の中心になっている)。文字コード問題の解決は意外に早いかもしれない。