EUCとはExtended Unix Code(拡張UNIXコード)の略で、もともと日本語UNIX諮問委員会がUNIXワークステーションの内部コードとして策定し、UNIXの開発元であるアメリカAT&T社に提案したものだったが、ISO 2022の拡張法に準じており、Open Software Foundation(OSF)、UNIX International(UI)、UNIX System Laboratories Pacific(USLP)という三団体が1991年に追認した結果、準国際的な規格として認知されている。日本では主にUNIXワークステーションで使われているが、中国と韓国では、UNIX畑のみならず、パソコンでも広く使われている。
ISO 2022の三つの拡張法のうち、EUCが採用したのは八ビット二階建方式である(六四ページ参照)。この拡張法では、ISOローマ字コードはそのまま0〜127の番号(GL領域)で使い、JISカナのようなローマ字以外のコードは文字番号に一二八を足して、128〜255に平行移動させ(GR領域)、八ビット(0〜255)の範囲に棲みわけさせたが、この方式でローマ字のコードと漢字のコードを共存させるのである。
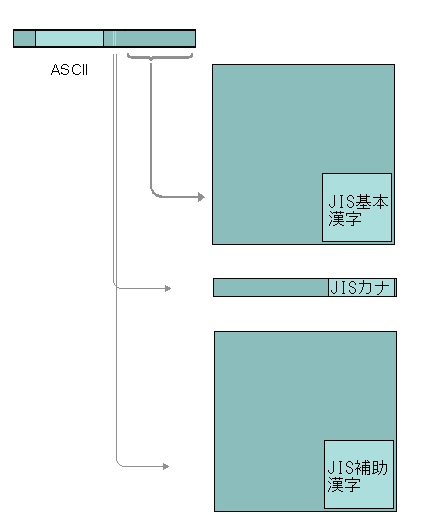
すなわち、日本語EUC(EUC-JP)の場合、JISローマ字をGL領域の番号で符号化し、JIS基本漢字をGR領域の番号で符号化する。中国語EUC(EUC-CN)ではGBローマ字をGL、GB基本漢字をGR、韓国語EUC(EUC-KR)ではKSローマ字をGL、KS基本漢字ハングルをGRで使う。
中国語、韓国語はこれで十分なのであるが、日本語の場合、半角仮名(JISローマ字カナのカナ)があるので、もう一段、凝ったことをやる。
この方式では二階建の二階部分の制御符号の番号(128〜159)が空いているが、そのうちの「142」と「143」を、タイプライターのシフトキーのように、文字盤切りかえ用に使うのである。ボドの印刷電信をタイプライターになぞらえて説明した際、シフトキーのように、次に打鍵する一文字だけをシフト状態にするシングルシフトと、文字盤をシフトした状態のままにしておくロッキングシフトがあると書いたのを思いだしてほしい(四八ページ参照)。
具体的には、「142」という制御符号を受信したら、次の符号をJISローマ字カナのカナ(いわゆる「半角カナ」)として解釈する。たとえば「ア」のGR符号は「177」であるが、EUC-JPで表す場合は頭に「142」をつけて、「142 177」という二バイトの符号であらわすのである。
シングルシフト用の符号がもう一つ(143)余っているが、こちらは後続する二つの符号をシフト状態にすることにして、JIS補助漢字用に使う。たとえば「鷗」のGR番号は「235 190」だから、シフト用の「143」を頭につけ、「143 235 190」とする。
EUCでは一般に「GL番号」でISOローマ字をあらわし、「GR番号」、「142+GR番号」、「143+GR番号」で、他の文字セットをあらわすようにする。つまり、EUCでは四つの文字セットを同時に使うことができるのだ(ISO 2022のG0〜G3にあたる)。
| 文字 | 10進 | 16進 | 符号長 | |
|---|---|---|---|---|
| JISローマ字 | A | 65 | 41 | 1バイト |
| JIS基本漢字 | あ | 164 162 | A4 A2 | 2バイト |
| JISカナ | ア | 142 167 | 8E A7 | 2バイト |
| JIS補助漢字 | 鷗 | 143 236 191 | 8F EC BF | 3バイト |
文字を一〜三バイトであらわす不定長コードになるが、これを「圧縮フォーマット」という。ただし、「半角カナ」を実装しているシステムは多くはないし、JIS補助漢字まで実装しているシステムとなると稀のようである。
EUC-JPにはすべての文字を二バイト固定長であらわす「EUC2バイト固定フォーマット」があるが、専門的になるので、本書では省略する。
Copyright 2000 Kato Koiti