デーヴァナーガリー文字は、古代ブラフミー文字に淵源する表記体系で、部品を組みあわせて一文字を表現する結合音節文字に分類される。サンスクリット、ヒンディー語などで使われており、使用人口は日本語人口よりも多い。インドには他にパンジャブ文字、グジャラート文字、ベンガル文字、タミール文字など、主なものだけで九の表記体系があるが、いずれもブラフミー文字起源であり、デーヴァナーガリー文字に似た構造をもち、大半の字母が一対一対応している。チベット文字、タイ文字、ビルマ文字、ラオスで使われるラオ文字なども、デーヴァナーガリー文字の影響下で生まれた表記体系である。デーヴァナーガリー文字に代表されるインド系文字の使用人口は数億におよび、使用地域も広大である。
デーヴァナーガリー文字にも母音字と子音字の区別があるが、ヨーロッパのアルファベットとことなるのは、音節文字だという点である。アルファベットは音素をあらわす音素文字なので、子音文字は子音しかあらわさないが、デーヴァナーガリー文字の子音字は子音の音節をあらわし、[a]という母音を潜在させている。
「川」をあらわす「ナディー」は ![]() とつづるが(横棒で連結された字形のまとまりが一単語である)、
とつづるが(横棒で連結された字形のまとまりが一単語である)、 ![]() だけで「ナ」という音節をあらわす。「ディー」
だけで「ナ」という音節をあらわす。「ディー」![]() は、「ダ」
は、「ダ」![]() と長母音の「イー」
と長母音の「イー」![]() を組みあわせている。
を組みあわせている。
長母音の「イー」は独立した文字としては ![]() と表記するが、子音字と組み合わせる際は
と表記するが、子音字と組み合わせる際は ![]() という字形をとる。前者を母音字、後者を母音記号と呼んで区別する。
という字形をとる。前者を母音字、後者を母音記号と呼んで区別する。
撥音や促音は子音字を重複させることであらわすが、子音字には[a]が含まれているのだから、単に重複させただけでは二音節になり、撥音や促音にならない。[a]をふくまない子音音節をあらわすにはいくつかの表記法があるが、一番わかりやすいのはハラント ![]() という記号(修飾子)を付加する方法である。「ダ」
という記号(修飾子)を付加する方法である。「ダ」![]() の場合、
の場合、 ![]() と表記することで、母音をふくまない子音音節をあらわすことができる。英国植民地時代にデーヴァナーガリー文字の打てるタイプライタが作られ、官庁などに導入されたが、機械的な制約から字母数が限られていたために、半子音字はハラントの重ね打ちで表現した。
と表記することで、母音をふくまない子音音節をあらわすことができる。英国植民地時代にデーヴァナーガリー文字の打てるタイプライタが作られ、官庁などに導入されたが、機械的な制約から字母数が限られていたために、半子音字はハラントの重ね打ちで表現した。
だが、ハラントの重ね打ちはあくまで便方であり、タイプライタ以外では使われないという。子音字には「カ」![]() のように縦軸をもった字が多いが、その場合、右半分を取りさって
のように縦軸をもった字が多いが、その場合、右半分を取りさって ![]() のように字形を替える。これを半子音字と呼ぶ。[kka]と同じ子音を重複させて促音をあらわすには、
のように字形を替える。これを半子音字と呼ぶ。[kka]と同じ子音を重複させて促音をあらわすには、 ![]() のように縦に重ねたり、
のように縦に重ねたり、 ![]() のように横につらねたりする(伝統的には縦方式だが、新聞などでは組版上の制約から、横方式が多い)。
のように横につらねたりする(伝統的には縦方式だが、新聞などでは組版上の制約から、横方式が多い)。
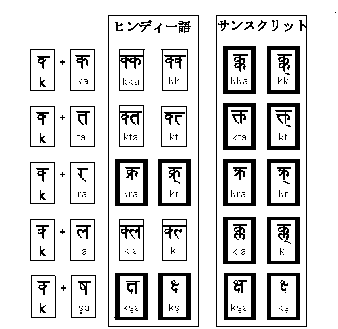
これだけでも十分複雑だが、本当にややこしいのはこれからである。半子音字と子音字の組みあわせは、さまざまなリガチャー(合字)になって、字形が替わるからだ。
二つの字が合体して、似ても似つかない字形に変化した文字をリガチャー(合字)という。日本人にはドイツ語の「β」くらいしか思い浮ばないが、世界の表記体系にはリガチャーを多用するものがすくなくない。デーヴァナーガリー文字もその一つで、「k」![]() と「シャ」
と「シャ」![]() で
で ![]() になり、「d」
になり、「d」![]() と「ヤ」
と「ヤ」![]() で
で ![]() になる。
になる。
デーヴァナーガリー文字はネパール語などでも用いられているほか、タミル文字、パンジャブ文字など、他の公用文字の転写にも使われているが、下の対応表のように、ヒンディー語とその古典語にあたるサンスクリット語ですらリガチャーが異なる。言語が特定できないと表示すらできない。
さらに鼻音化するために付加する修飾子二種と、 ![]() のように付加されるヌクタという流音化の修飾子がある。
のように付加されるヌクタという流音化の修飾子がある。
このような複雑な表記体系(インドから見れば、日本語の表記体系も複雑だろうが)を、コンピュータ化することが可能なのだろうか?
インドでは1970年代から、電子庁(DOE: Departnet of Electronics)をはじめとして、いくつかの機関が結合音節文字のコード化にとりくんでいたが、1983年にDOEは字形ではなく、音韻を符号化の対象とするという画期的な設計思想(有限音韻システム法)を打ちだした。1991年に正式にインドの国家規格となったIS 13194は、DOEの1983年のコードを原形としている。
IS 13194は、日本のJISローマ字カナと同じ7bitおよび8bitの文字コードだが、外部コードの層では字母を定義する一方、編集(テキスト処理)の層では、インドの各言語の共通音素をコード化した内部コードを定義し、外部コードにおける単位、テキスト処理における単位、表示処理における単位を階層化している。
| mbでの単位 | ||||||||
|---|---|---|---|---|---|---|---|---|
| WCでの単位
テキスト処理の単位 |
||||||||
| 図形での単位 | ||||||||
| 音節での単位 | ||||||||
上表は片岡裕「国際化・多言語化の基礎と実際」(『bit』1997年3-4月号)から引かせていただいたが、最上層の「mbでの単位」は外部コードにおける単位で、コード表に定義された字母というか文字部品がならんでいる(mbはマルチ・バイトの略)。キーボードに刻印されているのもこの文字部品で、入力する際は最上層にならんだ順序で打鍵していく。
先頭の![]() は「カ」で、次の
は「カ」で、次の ![]() は「アー」という母音記号、三番目の
は「アー」という母音記号、三番目の ![]() は鼻音化する修飾子である。第二層の「WCでの単位」はテキスト処理の上での単位であって(WCはワイド・キャラクターの略)、
は鼻音化する修飾子である。第二層の「WCでの単位」はテキスト処理の上での単位であって(WCはワイド・キャラクターの略)、 ![]() と
と ![]() は合体して、「アーン」
は合体して、「アーン」![]() という鼻母音になる。つまり、ここは音韻の層である。最下段は音節での単位で、「カーン」という音節をあらわす。
という鼻母音になる。つまり、ここは音韻の層である。最下段は音節での単位で、「カーン」という音節をあらわす。
最上層四番目の ![]() は「ガ」、五番目は母音をとりさるハラントである。二層目ではこの二つが合体して、半子音字
は「ガ」、五番目は母音をとりさるハラントである。二層目ではこの二つが合体して、半子音字 ![]() になる(
になる( ![]() から右半分をとりさった字形)。
から右半分をとりさった字形)。 ![]() は「ラ」、
は「ラ」、 ![]() は「エー」の母音記号で、合体すると
は「エー」の母音記号で、合体すると ![]() になる。純粋子音の
になる。純粋子音の ![]() と
と ![]() が表示階層で合体し、
が表示階層で合体し、 ![]() というリガチャーに替わる。音節としては[gre]である。
というリガチャーに替わる。音節としては[gre]である。
最後の ![]() は「サ」で、そのまま一音節となる。
は「サ」で、そのまま一音節となる。
IS 13194は九四字のコードであり、母音修飾子、母音字、子音字、母音記号、修飾子、インド数字という順で文字部品を配列しているが、これはソートを考慮した配置だそうである。また、入力を補助するための非表示操作子と、他の表記体系用の表示機構(リガチャー化する組みあわせは、表記体系によって異なる)に切り替えるための操作子が用意されている点も目を引く。インドには、デーヴァナーガリー文字をはじめとして、パンジャブ文字、グジャラート文字、ベンガル文字、タミール文字など、主なものだけで十の表記体系があるが、IS 13194ではデーヴァナーガリー文字のマッピングに対応させて、各表記体系のマッピングをおこなっている。そのため、表示階層を切り替えることで、フォント切替によって書体を変えるように、十の表記体系を一つの処理系でカバーすることができるのである。
なぜテキスト処理単位という階層を設ければならないのだろうか。なじみのない表記体系の話がつづいたので、少々乱暴だが、日本語に引きつけて説明しよう。
JISローマ字カナにはカタカナ(いわゆる「半角カナ」)が収録されている。JISローマ字カナは、一見、固定長コードのように見えるかもしれないが、濁点・半濁点が独立したコードになっているので、「ダ」や「パ」と表記する場合、「タ」+「゙」→「ダ」、「ハ」+「゚」→「パ」としなければならない。つまり、IS 13194やフランスのNF Z 62-010同様、不定長コードなのである。
表示するだけなら、「ダ」「パ」でも差し支えないが、挿入・削除・上書き・検索・置換・ソートといったテキスト処理をする段になると、とたんに問題にぶつかる。
テキスト処理上は「ダ」ないし「パ」で一文字だということがコンピュータにはわからないので、「タ」と「゙」の間に行の折り返しがはいったり、「パ」の「゚」だけをうっかり削除して「ハ」になったりしかねない。「モシ」→「モシモ」という置換をおこなうと、「モジ」が「モシモ゙」になる。ソートも困難である。
カナ文字には濁点・半濁点しかないので、この程度ですんでいるが、文字合成を広範におこなうデーヴァナーガリー文字では目茶苦茶になるし、単位を有限にしなければ処理ができない。そこでIS 13194では、有効な字母の組合せ(音韻)を限定しているのである。
ユニコードでは、正式な国家規格となる前の1988年版IS 13194が「2304」から「3455」までに収録されている。デーヴァナーガリー文字の字母は「2304」から「2431」までに配置されており、母音修飾子、母音字、子音字、母音記号、修飾子、数字という順序は踏襲されている。しかし、非表示修飾子と他の表記体系に切り替える属性子がない代りに、ヌクタつき子音字など、あらかじめ合成された15文字が数字の前に割りこんでいたり、ヌクタの相対コード位置も動いているなど、1991年版とはかなり異同がある。
表記体系間の対応関係はほぼ維持されており、デーヴァナーガリー文字の文字番号に128の倍数を加えることで、他の表記体系の対応字の文字番号をうることができる。独立の文字番号をあたえられた ![]() のようなヌクタつき子音字は、デーヴァナーガリー文字とパンジャブ文字でしか使われないので、他の表記体系の対応番号は空所になっている(ヌクタつき子音字は、辞書順ソートでは、つかない子音字と同様にあつかわれるから、独立の文字番号をあたえるとソートが難しくなると思われる)。
のようなヌクタつき子音字は、デーヴァナーガリー文字とパンジャブ文字でしか使われないので、他の表記体系の対応番号は空所になっている(ヌクタつき子音字は、辞書順ソートでは、つかない子音字と同様にあつかわれるから、独立の文字番号をあたえるとソートが難しくなると思われる)。
ユニコードは文字をコード化するという設計思想で作られており、音韻をコード化するというIS 13194の設計思想とは根本的にずれがある。ユニコードはもともと内部コードとして開発された。内部コードとして使うことで、プログラムが簡単になるなどのメリットがあるといわれているが、デーヴァナーガリー系の表記体系をテキスト処理しようとすると、テキスト処理上の単位ではなく、文字部品を対象にすることになり、先に述べたような混乱にみまわれる。世界中の文字カタログを作っただけでは、文字コードとして機能しないのである。
Copyright 2000 Kato Koiti