拙著『電脳社会の日本語』中でBTRON「超漢字」の「多言語環境」(PMC側の表現では「本格的多国語環境」)の問題点をとりあげ、アラビア文字とデーヴァナーガリー文字について「文字の体をなさない」と書いた点について疑問を呈した方がおられたので、具体例をあげて説明したい。本来はもっときちんと書きたいのだが、今、いろいろバタバタしている上に、「正誤表」を早く作らなければならないので、はなはだ中途半端であるが、ご容赦願いたい。

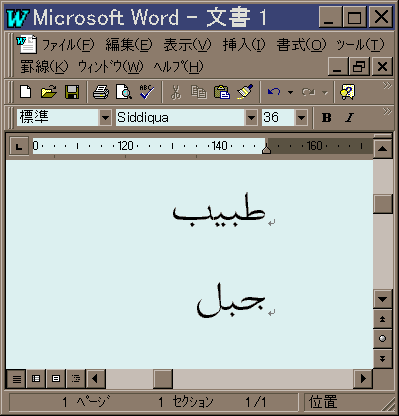
上左の図は「超漢字」で「医者」と「山」を意味するアラビア語をつづったところである(書式設定で、右詰を指定)。「超漢字」は文字送りピッチを調整して字母をつなげるが、上段は固定ピッチを、下段は比例ピッチを指定した状態である(といっても、つながっていないが)。上右に掲出したのは、Windows上でフリーのフォントでつづった同じ単語である。
一見して「超漢字」のアラビア文字が金釘流というか、アラビア文字の体をなしていないのはおわかりと思う。おそらく、このフォントの作者はアラビア文字を知らない人だろう。
字母がつながらないのも困るが、個々の字母にも問題がある。「医者」を意味するタビーブはt、b、y、bの四文字からなり(書字方向は右 → 左)、「山」を意味するジャバルはj、b、lの三文字からなる。アルファベットのbにあたる「バー」の語中形の「![]() 」は下の点が突起の真下にくるべきなのだが、「超漢字」の「
」は下の点が突起の真下にくるべきなのだが、「超漢字」の「![]() 」は点が左に寄りすぎていて、突起が連続すると、どの下に着くのかわからなくなるし、突起自体の書きぶりも気持が悪い。。
」は点が左に寄りすぎていて、突起が連続すると、どの下に着くのかわからなくなるし、突起自体の書きぶりも気持が悪い。。
アラビア文字は「表音文字」ということになっているが、通常、母音は表記しない。アラビア文字の読める人間は一まとまりの形状を見て単語を認知し、無意識に三つある母音のどれかを補って読むのである。
文字だけでいえば、ジャバルはジョビールかもしれないし、ジャボーリかもしれない。アラビア文字は当の単語を知らなければ発音できないので、表語文字(logogram)という。アラビア文字でつづった単語は漢字に近いところがあり、それだけに文字のリズムというか、流れが大きな意味をもつ。
下に「超漢字」でつづった単語と、Windowsでつづった単語を上下にならべておいた。「超漢字」の字形をアラビア文字と呼ぶのは勘弁してほしい。もし、こういうシステムを誇り高いアラブ諸国に売りこんだなら、日本は石油禁輸にあいかねないだろう。
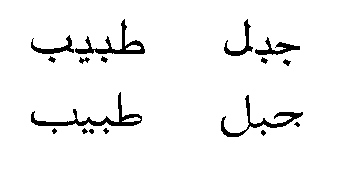
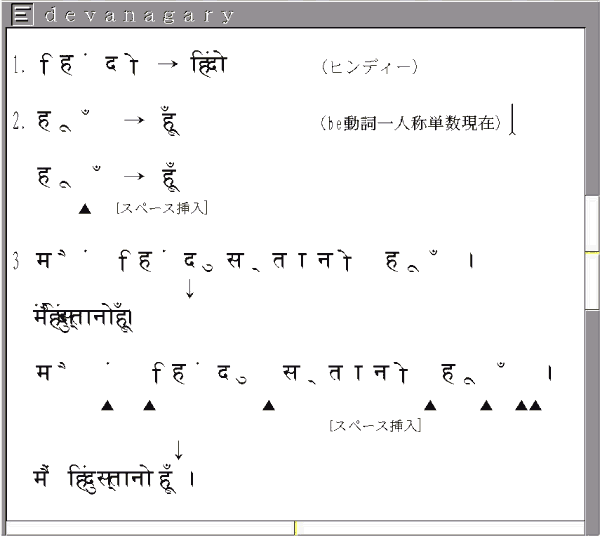
デーヴァナーガリー文字については、「『超漢字』管見」で使った図版を再度使わせていただく。
例文3は「マイン・ヒンドゥスターニ・フム」(わたしはインドの民である)だが、「超漢字」で普通につづると、3の二段目の

のように、ぐじゃぐじゃに重なりあってしまう。この例文では横棒(シローレカ)までつながってしまい、単語の切れ目がわからなくなる。
PMCに問い合せたところ、単語内部にスペースを適宜挟みこみ、字間調整を調整し、単語がつながってしまう箇所では、スペースを二つにすればよいという。アルファベットに転写すると、「Main Hindu stani hun.」を「Mai n iHndu stani hu n .」と表記するわけである。悪い冗談というほかはない(Windowsでは字間調整スペースなしでも、ちゃんと単語の形になる)。
さて、このようにスペースをはさめば、ちゃんと文の体をなすかというと、

のように、字間が一定しない上に、母音記号の位置がおかしい。
「わたし」を意味する「![]() 」は、「
」は、「![]() 」になるべきで、「超漢字」では母音記号の「
」になるべきで、「超漢字」では母音記号の「![]() 」が右に寄りすぎている。独立の単語だからいいようなものの、次に別の字がつづくと、「
」が右に寄りすぎている。独立の単語だからいいようなものの、次に別の字がつづくと、「![]() 」がどちらについているか、わからなくなる場合があろう。「
」がどちらについているか、わからなくなる場合があろう。「![]() 」が子音字と重なるのも気持が悪い。
」が子音字と重なるのも気持が悪い。
下に「超漢字」でつづった例文とWindowsでつづった例文を掲げる。

坂村健氏は「骨」という漢字の上の横棒が右につくか、左に着くかを重視し、右か左かを区別できなくなるユニコードを文字文化の冒![]() と批判しておられたが、「骨」なら、横棒が右につこうと、左につこうと、「骨」と読むことはできる。ところが、デーヴァナーガリー文字では母音記号や補助記号の位置がおかしいと、読めない場合があるのである(アラビア文字でも、一部の字母で同様の問題がおこる)。これは文字文化の冒
と批判しておられたが、「骨」なら、横棒が右につこうと、左につこうと、「骨」と読むことはできる。ところが、デーヴァナーガリー文字では母音記号や補助記号の位置がおかしいと、読めない場合があるのである(アラビア文字でも、一部の字母で同様の問題がおこる)。これは文字文化の冒![]() 以前の問題である。
以前の問題である。
なお、当り前の話だが、単語内部にスペースを挿入すると、単語の切れ目が識別できなくなる。上の例では、たまたま単語間にスペースが二つはいる形になっているが、単語間がスペース一つの場合もかなりある。つまり、編集ができなくなるのである。
「超漢字」リリースと前後して発売されたTRONWARE Vol.59には、PMCの住谷満氏が「本格的多国語環境へようこそ」という一文を書いている(抜刷がプレス資料として、TRONWARE発売前に取材者に配布された)。この文章には、
残念ながら超漢字の初期リリースにインド系言語の文字処理機構は登載されない注1)。しかし表示形(合字などの処理を施した後の文字)はそろっているので、文字としての表記は可能。
とあり、注1)として、「インド系文字」についての意味不明の解説があるが、注はともかくとして、「文字としての表記は可能」と明記してある。
実はユニコードのデーヴァナーガリー文字は試案段階のIS 13194をいれてあるので、「表示形(合字などの処理を施した後の文字)」ははいっていない。ユニコードを使ったデーヴァナーガリー・ワープロがあると聞くが、それらはいずれもユニコードを入出力コードとしてのみ使っているという。もちろん、表示はリガチャーや半子音字などの表示形を収録した別のコードでおこなう。
「超漢字」の場合、字形カタログの「スクリプト層」の上に、「文字属層」という編集用コードをのせるようであるが、表示形をもたないデーヴァナーガリー・コードをそのまま収録したユニコードを「スクリプト層」にいれてあるので、独自の拡張をおこなわない限り、ちゃんとした表示をすることはできない。だが、拡張をすれば、ユニコードとの互換性はなくなるだろう。
その一方、アラビア文字には表示形がはいっている(ペルシャ語、ウルドゥー語の固有文字も含む)。ユニコードは既存の文字コードを片端からいれていったので、性格を異にする文字が併存しているのである。そうした問題点に気づかず、ユニコードの文字セットを丸呑みしたつけはこれから回ってくる。その意味で、BTRON「超漢字」はユニコードのモルモットになったといってもいい。激烈なユニコード批判を展開していた坂村氏のシステムが、こういう末路をむかえるとは、なんとも皮肉な話である。
多言語編集が無理なことは最初からわかっていたが、昨年、拙著のために取材させていただいた際、多国語表示はできると断言しておられたので、文字の表示ぐらいはできるのだろうと思っていた。手作業で字母を組みあわせなければならないシステムを「本格的多国語環境」と称するのは問題であるが、上で見たように、それすらも無理だった。こうなると、誇大広告ではないかという人がいても不思議はないだろう。TRONファンの皆さんは疑問などは感じないだろうが、常識的にいえば、このような定説はおかしいと言わざるをえない(こちらからデーヴァナーガリー文字について上記の質問メールを出した後は、さすがにPMC側も「本格的多国語環境」という宣伝文句を引っこめたようであるが)。
お断りしておくが、わたしはマイナーなOSの足を引っ張ろうとか、商売の邪魔をしようと考えているわけではない。もし、足を引っ張るつもりなら、昨年11月の時点で、この事実を公表すればよかっただろう。だが、それでは多漢字環境の試みをつぶすことになりかねないので差し控えたし、「『超漢字』管見」で「多言語」の欠陥を指摘する際も、いろいろ余計な話をくっつけて、ショックのすくない形になるよう配慮した。
しかし、このような定説を放置しておくことは出来ない。「超漢字」が「本格的多国語環境」であるとか、世界中の文字を「いろいろなアプリケーションで自由に混在して利用できる」とかいう宣伝をマスコミが鵜呑みにして報じたために、多言語処理はすでに解決済という誤解が広まってしまったからである。
こうした誤解の蔓延は、地道に多言語処理を研究している研究者が開発を進める上で実害がないとはいえない。多言語処理技術はこれからの課題であることを、ぜひご理解いただきたいと思う。