

左から順に「原稿モード」、「詳細モード」、「清書モード」

「超漢字」は3B/V Release2というBTRON3仕様OSに、多文字機能を実装した製品である。パーソナル・メディア社は1994年から16bit版BTRON仕様OS、1B/Vを販売してきた。1B/Vは、松下電器が開発した同社の16bitパソコンで動くBTRON仕様OS、ET-MasterをAT互換機に移植したもので、1997年までに二度、改訂版を出している。
最終版の1B/V3はJIS基本漢字にくわえてJIS補助漢字、中国のGB基本漢字、韓国のKS基本漢字・ハングルを標準で搭載しており、2万5千字あまりの漢字と3千字近いハングル完成形、JIS補助漢字にはいっている拡張アルファベット(Çやâなど)が使えた。JIS補助漢字の拡張アルファベットは全角文字で、表示品質に問題があるが、方言まで数えれば、80近い言語が表記できるという。これを「とりあえず多言語環境」と呼ぶ。
1B/VはWWWでおなじみになったリンク機能をいち早く装備するなど、興味深いOSだったが、基本的に1980年代に作られた製品だった。ビデオカードのドライバがないために、アクセラレーション機能を使えないというハンデも負っていた。初心者向けをうたっていたものの、マニア向けの実験的な製品にとどまっていた。
アメリカ生まれのAT互換機が日本語をあつかえるようになったのは、漢字の複雑な字形を画面に表示するという手間のかかる作業を、本体のCPUではなく、ビデオアクセラレータという画面描画専用の小コンピュータにまかせたからだった。BTRONはWindowsとは違って、過去の重荷を引きずっていない身軽なOSであるが、ビデオカードのアクセラレーション機能を使えないので、レスポンスがかなり鈍かった。画面をスクロールさせると、二行単位でぎくしゃく動き、実用にはなりにくかった。
「超漢字」の前身の3B/V Release1は1998年11月に満を持して発売された、BTRON3仕様の新OSだった。本来なら、このバージョンがGT明朝6万4千字を登載した多漢字OSとしてデビューするはずであったが、GT明朝が間にあわなかったので、1B/V3と同じ「とりあえず多言語環境」を提供するにとどまった。
「超漢字」こと、3B/V Release2は今年(1999年)11月に発売されたが、またしてもGT明朝は間にあわなかった。しかし、GT明朝をしのぐ8万字の漢字と、甲骨文字、西夏文字、水文等を収録した今昔文字鏡と提携したので、文字鏡の文字セットと、台湾のCNS 11643の最初の二面、ユニコードの非漢字レパートリーを登載し、「超漢字」という名称をあたえた。このあたりの事情は「2000年紀の文字コード問題」の「超漢字」の項に書いておいた。
GT明朝(現在は「GTコード」)はBTRON上にネイティブな環境をもつ点がメリットだったが、来年、「超漢字」に載るとしても、この一年の遅れは決定的であり、大文字セットのデファクト・スタンダードは文字鏡に決ったと考えてよい。
「超漢字」という名称であるが、好みの問題が大きいので、あれこれいうことは控えたい。ただ、日本語に関心の深い人を、ユーザーに想定しているとするなら、このネーミングが賢明でなかったということは言える。若者の間にはやっている「チョー○○」という語法に顔をしかめる人はすくなくなく、「超漢字」という名称にいい印象はもたないだろう。
「超漢字」を立ちあげて、まず気がついたのは、画面デザインがよくなったことである。昨年の3B/V R1の時点で、画面解像度と色数については現在のレベルに達したが、デザインはあいかわらずだった。
次に気がついたのは、レスポンスが速くなり、スクロールさせても画面が波うつようなことがなくなったことである。アクセラレータが使えないので、Windowsのようにすいすいスクロールというわけにはいかないが、十分、実用のレベルである。わたしが「超漢字」をインストールしたマシンのCPUは K6-2 400MHzだから、現時点における平均的な性能のパソコンなら、ストレスを感じることはないだろう。一年でよくぞここまでオプチマイズしたものである。
キーボードの排列が一般的な109キーボードをほぼ踏襲する形になったのも、けっこうなことである。AT互換機用OSである以上、109キーボードを使うケースがほとんと思われるのに、昨年までは、デフォルトがTRONキーボードもどきの排列になっており、ESCキーを押すと「単語登録」のメニューが出てきて面食らったものだった。
せっかくキー排列が109に近くなったのに、機能のショートカットはBTRONのままで、変えられないようだ。Windowsのつもりで、CTRL+ZでUndoしようとすると、文字列を貼りつけてしまったり、CTRL+Vで文字列切り取りになってしまったりで、神経が疲れる。デフォルトまでWindowsに合わせろとは言わないが、ショートカットは無意識的に使うものなので、変更できないと困る。
BTRON仕様OSにはInsertキーとDeleteキーという概念が一般のパソコンと違うので、Insertを押して上書と挿入を切り換えるとか、Deleteでカーソル位置の一文字を削除するといった手になじんだ操作はできない(TRON作法では、Deleteはオブジェクトの削除に特化)。
Deleteキーによる一文字削除は頻繁に使うので、BSでしか文字が削除できないのはひじょうにストレスがたまるし、「多言語機能」の項で述べるような問題もある。しかし、OSの基本仕様に係わる事項であるから、将来もこのままだろう。
日本語IME(仮名漢字変換)は3B/V R1からVJE Deltaになった。1B/Vの時代は、松下電器の1980年代のワープロ専用機に使っていた仮名漢字変換ソフトを流用していて、とても使えたものではなかった。歴史のあるVJEの採用は格段の進歩だが、なぜかカスタマイズ機能は実装されず、1B/Vの操作系を踏襲していた。日本語IMEショートカット同様、無意識的に使うものなので、カスタマイズできないのは致命的だった。今回、遅ればせながら、カスタマイズ機能がついたことは評価したいが、VJE Delta版しかないのは残念である。ATOKやWXを使ってきた人にとっては、手になじんだ操作法が使えず、辛いだろう。Windows版のVJEのカスタマイズ機能はよくできているから、そっくり移植した方がよいと思う。
VJEはATOKよりもヒット率が低いが、動作がきびきびしていて、操作系が小回りが利くので、総合的な性能では、ATOKと較べても、決定的に劣っているわけではないと思う。ところが、「超漢字」のVJEは動作がひどく重い。
VJEには半角カタカナの候補を自動生成し、勝手に単語登録してしまうというオバカな機能があって、いつも苛立たしい思いをしているのだが(残しておくと、どんどんうざったくなるので、定期的にユーザー辞書から半角カタカナ語を削除している)、なんとこの機能は3B/V版にもついていた(さすがに単語登録まではしないが)。半角カタカナの必要度は減っているし、別の手段でも出せるのだから、こういう問題のある機能は移植しない方がいいと思う。
VJEはいろいろな点でATOKに差をつけられているが、わたしがVJEを手放せないでいるのは、「無変換」キーで直前に入力した文字列を呼びだす機能と、全角モード時に「変換」キーで半角スペースを入力する機能があるからである(半角モード時には全角スペース)。この二つの機能、特に前者の機能は実に便利で、VJEの基本性能の低さを補ってあまりある。ATOKをVJE風にカスタマイズして、しばらく使ったことがあるが、「無変換」キーの機能までは再現できないので、結局、VJEにもどってしまった(注)。
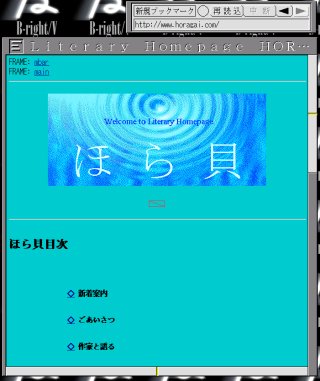
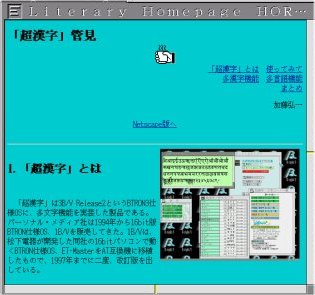
今回、やっとダイアルアップ接続と専用ブラウザがついた。内蔵モデムを認識しなかったので、ずっと使えなかったが、昔、使っていた外付モデムが見つかったので、早速試してみた。まず、「ほら貝」のトップページを出したところ、フレームに対応していないので、左のような表示になった。ブラウザ・ウィンドウ自体にはボタン類はつかず、別に操作用ウィンドウがポップアップする。このページに飛ぶと、右のようになる。Javaにも対応していないので、「ぴあ」など、Javaでコンテンツに飛ぶ作りのサイトでは内容にたどりつけない。Javaの使いすぎはいかがなものかと思うが、Javaは当り前になりつつあるので、早急な対応が望ましい。
12万字の漢字を正規の文字として使えるのが「超漢字」の最大のメリットだとわたしは受けとっている。文字鏡の八万字の漢字はWindowsやMacintoshでも使えるが、裏フォント方式や実体参照になるので、情報交換は一応できるものの、単語登録はできないし、検索もできない。「超漢字」は情報交換に難があるが、シームレスに使える意義は大きい。しかし、現状は文字がはいるというレベルにとどまっている。
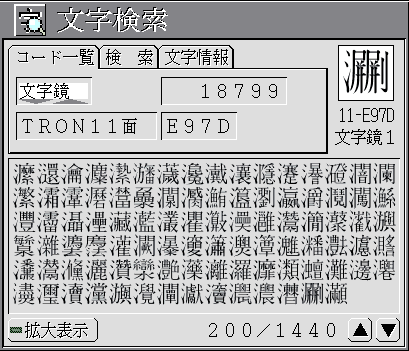
唯一の漢字ナビゲータである「文字検索小物」は、画面を御覧になればおわかりのように、候補の字が見にくい。「器」のように「口」を四つふくむ漢字を探すのに「口*4」と打ちこむとか、さまざまな検索式を用意しているが、式をおぼえろというのは理科系の発想で、文科系人間にとっては辛いものがある。定価二万八千円の「文字鏡」の検索ツールと較べるのは酷かもしれないが、この程度のツールで一二万字の漢字を使いこなすのは、土台、無理な話だ。

大文字セットに絶対に必要な異体字シソーラスを使った曖昧検索機能は用意されていないので、異体字検索は手作業でおこなわなくてはならない。手作業というのは、検索小物の関連字情報で、異体字関係にある漢字を一覧し、コピー&ペーストで基本エディタの検索ウィンドウに貼りつけ、一字づつ検索するわけであるが、実際にやってみるとわかるが、とうてい実用にならない。「 『アジアの漢字と文献処理』レポート」に紹介したCD-ROM版「四庫全書」の検索機能のような、複数のレベルをもった異体字検索が緊急に必要である。
検索小物の関連字情報はJIS基本漢字・JIS補助漢字・文字鏡文字に限られているので、中国漢字や台湾漢字、韓国漢字を検索するには、コード表から探し、コピー&ペーストしなければならない。

GB基本漢字については「中国語入力」という小物がある。小物メニューから「中国語入力小物」をクリックすると、小さなウィンドウが出現する。小物ウィンドウが画面のどこかに出ている状態で、ローマ字入力モードで「zhu2」のようにピンインを打ちこむと、小物ウィンドウに候補の漢字が数個表示される。目当ての漢字を選択すると、基本エディタにその漢字が転送される(うまくキャプチャーできなかったので、画面は省略)。
一字一字ひろっていくわけであるから、中国語IMEというより、ピンイン検索ツールというべきだろう。これで文章を入力するのは無理である。この小物であつかえるのはGB基本漢字だけで、CNS台湾漢字に対応していないことも、申しそえておく。

「超漢字」は多言語機能をうたっており、広告やマニュアルでもデーヴァナーガリ文字、タイ文字、チベット文字など、結合音節文字が、すべてのアプリケーションで「自由に使える」と書いてあるが、実際はどうだろうか。
「超漢字」の場合、Unicode2.0をそのままもってきているが、「多言語テキスト処理はどこまで可能か」で指摘したように、Unicodedでは文字の表示は出来るが、編集は出来ない。FAQ集では、「デヴァナガリ語やアラビア語などの言語固有の表記規則に対応しておりません」と断ってあるが、実は表示も怪しいのである。
デーヴァナーガリ文字がどういう表記体系かについては、「多言語テキスト処理はどこまで可能か」を読んでいただきたい。簡単に言うと、字母を組みあわせて一文字を作るのだるが、「超漢字」が実装したUnicodeフォントは、Windowsのデーヴァナーガリ・フォント同様、プロポーショナル・フォントの文字送りピッチを逆方向に設定することで、重ね打ち的な合成をおこなっている。重ね打ちであるから、リガチャーはまったく表示できないし、半子音字もハラントを付加する形でしか表現できない。Unicode2.0でデーヴァナーガリ文字が表示できるといっても、イギリス植民地時代に広まったデーヴァナーガリ・タイプライターのレベルにとどまるのである。
なお、「超漢字」のデーヴァナーガリ文字のコード表(上図の左上の黄緑色のウィンドウ)の最下段は、前置される母音記号![]() の位置から行頭まで、表示が乱れている(同様の現象はタイ文字などのコード表でも起こっている)。
の位置から行頭まで、表示が乱れている(同様の現象はタイ文字などのコード表でも起こっている)。
さて、下図左側は固定ピッチのままの状態、右側は比例ピッチ付箋をつけて、重ね打ち的合成をおこなった状態である。

1の「ヒンディー」という語は、Hindyと綴るべきところを、「i」にあたる母音記号![]() が前置されるために、iHndyと綴っている。こういう形でデータを記録するのは問題である。
が前置されるために、iHndyと綴っている。こういう形でデータを記録するのは問題である。
2は英語の am(be動詞の一人称単数現在)にあたる「フーン」という動詞である。「ハ」+「ウー」+鼻音化記号を組み合せるが、そのままだと鼻音化記号の![]() が左にずれてしまい、どの音節についているかわからなくなる。PMCに問い合せたところ、スペースを挿入すると表示できるというので、早速やってみた。スペースを入れると、下のように真上に来るが、「hun」を「hu n」のように綴ることになり、単語を分断してしまう。
が左にずれてしまい、どの音節についているかわからなくなる。PMCに問い合せたところ、スペースを挿入すると表示できるというので、早速やってみた。スペースを入れると、下のように真上に来るが、「hun」を「hu n」のように綴ることになり、単語を分断してしまう。
3は「わたしはインド人です」を意味する「Main Hindustani hun.」という文だが、そのままだとグジャグジャになって、文字の体をなさない。
そこで、スペースを7箇所いれて調製したのが下の行である。TRONコードで記述したとおりにローマ字に転記すると、「Mai n iHndu stani hu n .」となり、原形をとどめないくらい変形している。「言語固有の表記規則に対応」するかどうか以前の問題である。
母音記号の位置は、「超漢字」の問題というより、フォントの品質の問題かもしれない。フリーで公開されているWindows用のMantraフォントを使うと、![]() が
が![]() と表示される。
と表示される。
字母を手作業で組みあわせるなら、Windowsの方が楽である。「超漢字」の場合、Deleteキーが使えないので、修正のために字母を削除するにはBSキーを使うしかない。ところが、比例ピッチ付箋を指定したままだと、BSキーでは消せない字母があるのだ。そこで、比例ピッチと固定ピッチを切り換えながら作業せざるをえず、Windowsよりも余計に手間がかかる。
もっとましなフォントに取りかえれば、「超漢字」の多言語機能は使えるようになるだろうか?
無理ではないか、と思う。Unicodeのデーヴァナーガリ文字をはじめとするインド系の文字は、IS 13194の1988年版のコード表をそのまま収録しているが、この時点のIS 13194は試案段階にすぎず、1991年版にいたって、ようやくインドの国家規格となっている。
IS 13194は有限音素システムという独特の設計思想で作られているが、1988年版はこの思想が不徹底だったために、矛盾をきたすという。「超漢字」はUnicodeを丸呑みしたために、Unicodeの欠陥までも継承してしまったのだ。
ここで指摘したような問題はタイ文字やチベット文字でもおこる。アラビア文字系の表記体系では別の問題がもちあがるが、それについては「2000年紀の文字コード問題」のISO 2022対ユニコードを参照されたい。
「ようこそ多漢字の世界へ」というデモ文書に文字コードに関する解説があるが、「JISコードを多国語に拡張したISO−2022コード」というくだりなど、事実に反する記述が目につく。現在のTRONコードはISO 2022そっくりの設計になっており、ISO 2022の存在を無視しなくては独自性(?)をアピールできないという事情はわからなくもないが、妙な「定説」を広めるのはいかがなものか。
TRONコードが他のOSに採用される可能性はないと思う。TRONコードを内部コードにするということは、ISO 2022を内部コードにするのと同じ困難をまねく。ISO 2022が内部コードとして使いにくいというのは周知の事実であって、だからシフトJISやEUCのような文字コードが考案されたのだ(厳密にいえば、EUCもISO 2022の一部だが)。ISO 2022は外部コードとして設計されたものであって、Muleのように、独自の内部コードに変換してから処理するのが本来のあり方である。ISO 2022と酷似した構造をもつTRONコードを内部コードとして採用するOSベンダーがあるとは考えにくい。
現在の文字コードをめぐる状況を一口で要約するなら、圧倒的な歴史のあるISO 2022の世界を、ユニコード=ISO 10646が懸命に切り崩そうとして、切り崩しきれないでいる、ということになろう。
外部コードとして見た場合、ISO 2022には一つ、欠陥がある。多バイト系のISO 2022系コードでは第一バイトと第二バイトが判別できないのである(TRONコードも同様の欠陥をもつ)。ユニコード=ISO 10646ではデーヴァナーガリ文字のような結合音節文字の処理に限界があるので、ISO 2022にもどるか、第三の国際文字コードが作られるかのいずれかになる公算が高いが、もし第三の国際文字コードが出来るとしたら、UTF-8のように先頭バイトと後続バイトを区別できるような構造のコードになるような気がする。
「超漢字」は3B/Vの第二版にあたるが、第一版と較べると格段に速くなっており、使い勝手の面でも、一般ユーザーを意識したものになっている。昨年までのBTRONとは一線を画する製品といえよう。すくない人員でここまで練りあげたPMCの開発陣にエールを送りたい。
だが、多漢字のシステムとして見た場合、課題はあまりにも多い。BTRONを至上のものと崇拝する人なら現状のままでも満足だろうが、漢字を使いたいだけのユーザーには勧めにくい。
多言語機能に関しては期待しない方がよい。見せかけだけの多言語機能に開発人員を割くくらいだったら、漢字のシステムとしての整備に注力すべきだったのではないかと考えるしだいである。
最後にデータ交換について。「ファイル変換」小物でWindowsファイルにテキストを変換すると、JIS文字セットにない文字は、警告した上で「〓」に置きかえられるが、クロスプラットホームの文字鏡の文字まで「〓」になるのは承伏できない。
HTML形式(これもテキスト・ファイルである)にし、文字鏡文字は文字鏡サイトのgifサービスで表示するとか、文字鏡フォントをインストールしてあることが条件だが、HTMLのフォント・タグで指定することができるはずである。また、実体参照を使えば、HTML形式でなくても、文字鏡文字を使うことが出来る(Word用のマクロがある)。
JIS補助漢字はそのままの形では無理だが、文字鏡にすべて含まれているのだから、ユーザーに確認した上で文字鏡文字に置きかえれば、他のプラットホームにもっていくことができる。
「超漢字」は、結局、多漢字システム以上のものではないが、文字鏡を介せば、Windowsだけでなく、Macintosh、Linuxなどでもデータを共有することができる。実用の見地からいえば、それでほぼ用は足りるはずだ。一日も早い対応を望む。
Copyright 1999 Kato Koiti