文学系WWWのための 5tips
加藤弘一
HTML作成ソフトはWWWページ作成を容易にしてくれました。最近のHTML作成ソフト、たとえばIBM HomePage Builderあたりは、作ったページをサーバーへ自動的に転送したり、リンクの有効性をチェックするところまで面倒をみてくれるので、ワープロを使える程度の知識があれば、簡単にWWWページを公開することができるようになりました。
しかし、市販のHTML作成ソフトでは、最新の表現方式はサポートしていません。このページでは文学系WWWページを作っている方を対象に、WWWページの表現力を高める+αの技を五つ紹介します。
- 行間を拡げる
- JIS基本漢字にない文字を出す(機種依存文字でなく)
- 漢字にルビをふる
- 縦書をまぜる
- ソースをいじる
1〜3は裏技ではなく、HTMLとXMLを仕切っているW3C勧告にもとづいた正式の方式です(3のルビは2001年5月31日にRuby Annotation W3C Recommendationになりました)。以前のような一社だけで勝手に決めた独自仕様ではない点を強調したいと思います。4もW3Cで検討中の方式なので、将来的には正式勧告になるでしょう。
1はIBM HomePage Builderでも設定できますが、2以降はソースを変更しなければならないので、5でソースの簡単な編集方法を紹介します。
なお、文中、Internet ExplorerはIE、Netscape NavigatorはNNと略記します。
1. 行間を拡げる
W3CはWWWページのレイアウトは、HTMLではなく、スタイルシートで指定するよう、推奨しています。スタイルシートは多彩な表現力をもっていますが、中でも行間を広げて、読みやすいページを作る技は、文学系ページにとって重要です。
IBM HomePage Builderでは、「サイト」メニューからページのタイトルを選び、そのタイトル用のスタイルシートを設定するようになっているようです。IBM HomePage Builderのユーザーの方は、マニュアルにしたがって、あらかじめ用意されているスタイルシートから選択すればよいでしょう。
スタイルシート設定機能をもっていないHTML作成ソフトをお使いの方や、手作業でHTMLソースをお書きの方は、まず、スタイルシートをダウンロードしてください。下の「my.css」にマウスカーソルをあてて、右クリック、「対象をファイルに保存」を選んで、WWWページをおいてあるフォルダーに my.cssという名前で保存してください。
次に、WWWページにスタイルシートを読みこむためのリンクをソースに書きこみます。
ページの先頭は以下のようになっていると思います。
<HTML>
<HEAD>
<TITLE>いろはにほへと</TITLE>
</HEAD>
<HEAD>と</HEAD>にはさまれた部分に
<link rel="stylesheet" type="text/css" href="my.css">
という一行をを貼りつけます。上記のソースでいうと、
<HTML>
<HEAD>
<TITLE>いろはにほへと</TITLE>
<link rel="stylesheet" type="text/css" href="my.css">
</HEAD>
となります。これで終りです。「更新」をクリックして、行間が拡がっていることを確認してください。
なお、スタイルシートはIE4以上、NN4以上が対応していることになっていますが、NN4のスタイルシート機能はかなり問題があり、思ったような効果がえられないことをお断りしておきます。
2. JIS基本漢字(JIS X 0208)にない文字を出す
JIS基本漢字(JIS X 0208)にない文字をWWWページで出す方法としては画像貼りこみ方式がありますが、ブラウザから語句をコピーした場合、画像貼りこみの文字が抜けてしまうという短所がありました。たとえば、
内田百

先生
をコピーして、ワープロかメモ帳に貼りこんでみてください。「内田百先生」になるはずです。
しかし、下の場合は違います。
内田百閒先生
「内田百閒先生」という文字列を貼りつけることができるでしょう。こんなことができるのは「数値文字参照」といって、ISO 10646(≒ユニコード)の文字を直接指定する技を使っているためです(一時、「実体参照」と表記していましたが、正しくは「数値文字参照」でした。訂正します)。
というと、システム外字(機種依存文字)を使っているのではないか、ネットでシステム外字(機種依存文字)は御法度のはずだが……と思う方がいらっしゃるかもしれません。
しかし、それは誤解です。システム外字(機種依存文字)とは、公的規格にない文字をメーカーが勝手な符合位置に配置した文字のことをいいますが、をあらわす「38290」はISO 10646という国際規格における符合位置であり、メーカーが勝手にマッピングしたシステム外字(機種依存文字)ではありません(ISO 10646の符号表はユニコード符号表と同一であり、JIS X 0221として日本の公的規格にもなっています)。
ただし、フォントにその符合位置に対応するグリフ(字形データ)がはいっていなければ表示されません。問題はOSの種類やバージョン、ユニコード・フォントの種類(MS Officeにおまけでついてくる Arial Unicode MSには BMP内の全漢字がはいっているようです)によって、グリフ数に違いがあることです。グリフ実装のズレによって表示されない文字は、システム外字(機種依存文字)と区別するために、グリフ抜け文字と呼ぶべきだと思います。
システム外字(機種依存文字)の場合は文字化けが起こったり、異常動作が起こったりするので、絶対に使うべきではありませんが、グリフ抜け文字の場合は単に表示されないだけですし、どういう文字か知りたければ、Unihan Databaseで調べることができます。グリフ抜け文字を使ったがために、一部の読者を失う可能性はありますが、その覚悟があるならば、害を及ぼすわけでないので、使う・使わないはページ作成者の判断にまかされるべきです。
さて、ISO 10646(≒ユニコード)の文字を使うにはページをUTF-8でつくるのが正式の方式ですが、シフトJISのページでも上記の「数値参照」という手法(W3Cの規格にあります)でもできます。
方法は簡単です。ソースを開いて、「」と書きたい部分に「閒」と書きこむのです。文字番号はユニコード文字表で調べることができますが、わたしは「今昔文字鏡」の「形式を選択してコピー」の「Unicodeタグ(10進数)」を使っています。
最初はWWWだけで使っていましたが、読書記録や原稿などにも、数値参照でユニコード漢字を使うようになりました。画像貼りつけはめんどくさいので、無意識のうちに自己規制していたようですが、数値参照を使うようになってからはなし崩し的にJIS基本漢字以外の漢字の使用が増えています。
問題はどういう字なのか、わからなくなることです。特にhtml以外の文書で使うと、ちょっとブラウザで確認というわけにいかないので深刻です。しかし、杉本雅広氏が「文字参照ツール」を公開されたことで、難点が解決されました。これで安心して数値参照でデータを蓄積することができます。
なお、よく使う漢字は単語登録しておくといいでしょう。以下に作家の名前をあげておきます。
- うちだひゃっけん
内田百閒
内田百閒
- さとみとん
里見弴
里見弴
- もりおうがい
森鷗外
森鷗外
類似の方式で「ç」や「ö」、「£」なども出すことができます(WordやExcelのようなユニコード対応ソフトなら、貼りつけも可能)。
IBM HomePage Builderでは、「ç」や「ö」、「£」などは「挿入」→「特殊文字」で、一覧表から選んで書きこめるようになっていますが、漢字の場合はソースをいじるしかないようです。
なお、NN4では、Windwos外字にないユニコード漢字は「?」になります。NN4でユニコード漢字を表示するにはUTF-8を使う必要がありますが、ISO 10646のJ欄にある文字の範囲しか表示できません。NN6ではシフトJISページでも、フォントにはいっているすべての漢字を表示できます。
IE5xでは lang="ja"と日本語であることを明示すると、ISO 10646のJ欄の範囲に制限されますが、言語指定を削るとフォントにあるすべての漢字が表示できます。
以下はUTF-8を使ったサンプル・ページです。
- 内田百閒
- 森鷗外
UTF-8ならNN4でも表示されますが、使いなれたツールが使えませんので、しばらくはシフトJISで数値参照を使うことになりそうです。
3. 漢字にルビをふる
今のところ、IE5以上のみの対応ですが、Ruby Annotation W3C Recommendation 31 May 2001として、正式に勧告になったので、他のブラウザやHTML作成ソフトもしだいに採用していくでしょう。
どんなふうに見えるかというと、
と、正真正銘のルビがつきます。未対応のブラウザの場合は、一種の下位互換が成立していて、「里見弴(さとみとん)」のように新聞方式で見えますから、安心して使えます。
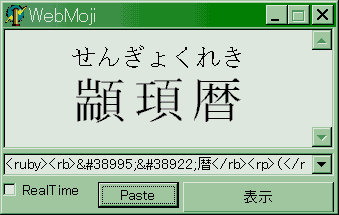
杉本雅広氏により、Rubyというルビ入力ツールが公開されています。ソースのいじれる人なら、これで簡単にルビの恩恵を受けるようになりました。
手書き派の方のために上記のソースを示すと、次のようになります。
<RUBY><RB>里見弴</RB><RP>(</RP><RT>さとみとん</RT><RP>)</RP></RUBY>
複雑なので、すこしだけ解説します。下図をご覧ください。
<RUBY>
</RUBY>
<RB>
里見弴</RB>
<RT>
さとみとん</RT>
<RP>
(</RP>
<RP>
)</RP>
一番外側(第一層)の「<RUBY>」と「</RUBY>」は、間にはさまれた文字列がルビつき語句を定義していることをあらわします。
第二層の「<RB>里見弴</RB>」はルビの対象となる語句をあらわします。第三層の「<RT>さとみとん</RT>」がルビであることもわかりますね。
問題は第四層の「<RP>(</RP>」と「<RP>)</RP>」です。これはなくてもよいのですが、ルビ未対応のブラウザのための配慮でいれています(ルビ対応ブラウザでは表示されない)。
これを入れると、ルビ未対応のブラウザでは「里見弴(さとみとん)」と表示されますが、入れないと「里見弴さとみとん」となり、ルビであることがわからなくなります。
なお、振り仮名の代わりに「
ヽ
ヽ」を<RT>ではさめば傍点風に見えますが、「ヽ」は躍字であって、傍点ではないので、お勧めできません。
 IE5.5の場合
IE5.5の場合
 NN4.7の場合
NN4.7の場合4. 縦書をまぜる
縦書は、当サイトで紹介したQTViewなど、いろいろな方法が試みられていますが、縦書の状態に整形する行き方には賛成できません。コピーして、別ウィンドウに貼りつけるとわかりますが、縦書に見えるように文字を並べた結果、暗号のような滅茶苦茶なテキストになっています。
幸い、W3CではHTML国際化の一環として、縦書スタイルシートを検討中です。
ここで紹介するのは、W3Cの動向を先取りしてIE5.5が実装した方式で、縦書の体裁はスタイルシートで規定し、ソース側は対象となるテキストを縦書タグではさむだけです。ルビ・タグ同様、いずれW3C勧告になると思われますが、万一、仕様が変更になったとしても、スタイルシートを変更するだけでよく、ソースの保守に困ることはないと思います。「1. 行間を広げる」のスタイルシートに「tate」という名称で定義しておきましたので、縦書にしたい文章を<p class="tate">と</p>というタグではさむだけでOKです。
たとえば、IE5.5以上ですと、次のように見えます。
未対応のブラウザでは、普通に横書で表示されます。
W3Cが縦書の実現に努力している点は歓迎したいですが、「原稿グリッド」と称して、原稿用紙の罫線までスタイルシートで実現しようというのは馬鹿げています。原稿用紙の罫線は、手書きの不揃いな文字をすこしでも見やすくするために生まれた必要悪で、コンピュータの整然とならんだ文字の上に重ねたら、読みにくくなるだけなのですから。
5. ソースをいじる
いろいろなやり方がありますが、一番簡単なのはIEで読みこみ、「表示」→「ソース」で「メモ帳」にソースを読みこませる方法です。「メモ帳」は、一応、テキスト・エディタですから、ソースを編集することができます。
ただ、「メモ帳」は使いにくいですから、Dummy Padなどで、好みのエディタに変更した方が賢明です。文字コード自動識別機能のついたsakuraあたりがよいでしょう。
お勧めしたいのはKazuasa氏が公開されているFileGrepというツールです。これはフォルダー(ディレクトリ)内のすべてのファイルで語句を全置換するもので、「鴎外」を一瞬で「鷗外」に変換することができます。
言うまでもないことですが、ソースをいじる場合は、必ずバックアップをとっておくことをお勧めします。
Copyright 2001 Kato Koiti
This page was created on Apr17 2001; Updated on Sep16 2001.

