インターネット上の漢字について語るためには、遠回りのようだが、まずASCIIとISO/IEC 2022という文字コードの規格からはじめる必要がある。ASCIIは1963年、ISO/IEC 2022は1972年の制定だが、インターネット上の文字のやりとりはこの二つの規格を土台にしているからだ。
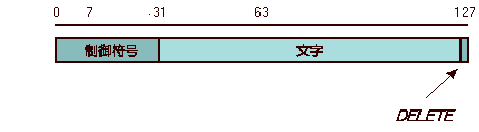
ASCIIとはAmerican national Standard Code for Information Interchange(情報交換用アメリカ国家標準コード)の略で、一文字を7ビットの二進数――000000から1111111まで(十進法の0〜127)の128の番号(符号)――であらわす。
符号がつけられる対象には有形の文字だけでなく、「送信開始」、「印字位置を左端にもどす」、「ベルを鳴らす」など、通信の段取もふくまれる。後者は無形の機能であり、文字ではないが、通信上は文字と同等にあつかわれるので、「制御文字」、「制御符号」等と呼ぶ。それに対して、通常の文字は「図形文字」Graphic Characterと呼ばれる。制御符号に使われる符号範囲は制御符号領域、文字に使われる符号範囲は文字領域と呼ぶことが多い。
IBM社の文字コード(EBCDIC)などでは制御符号領域と文字領域が混在していたが、ASCIIは制御符号領域を0〜31[16進数では00〜1F]という冒頭部分にまとめ、文字領域と明確に分離している。ただし、歴史的な経緯から、127[16進数の7F]はDeleteという制御符号に割りあてられている(注1)。
|
ここで注目していただきたいのは、規格名に明示されているように、ASCIIは「情報交換用(for Information Interchange)」文字コードだということである。ASCIIに限らず、公的規格となっている文字コードはいずれも情報交換用文字コードである(ただし、後述のISO/IEC 10646はやや性格が異なる)。
内部処理はどんな文字コードでやってもいいが、情報交換をおこなう際には公的文字コードに変換して出力するというのが文字コード標準化の基本的な考え方である。情報交換用文字コードは外部に出力されるので「外部コード」、内部処理用文字コードは「内部コード」と呼ばれることが多い。
ASCIIは後発の文字コードだったが、設計がすぐれていたので、1967年にISO R 646というISO(国際標準化機構)の規格になり(後にRがとれてISO 646になる)、翌1968年にはCCITT(国際電信電話諮問委員会)にも採用された。ISO加盟諸国の公的文字コードはいずれもISO 646をもとにしている。
ASCIIは英語を記述するには十分だったが、åやöのようなダイアクリティカル・マークつきアルファベットを使うヨーロッパの言語には不十分である。
ISOでは12の番号(符号)をナショナル・ユース・ポジションとし、加盟国の事情にあわせて文字を入れ替えてよいとした。たとえば、ASCIIで「\」が割りあてられている92[16進数では5C]はドイツでは「ö」、フランスでは「ç」、スペインでは「Ñ」、日本のJIS C 6220(現在はJIS X 0201)では「¥」になる。
一国内のみで情報交換するなら、ナショナル・ユース・ポジションを意識する必要はないが、国際的な情報交換では文字化けが生じる。アメリカ版のWindowsではディレクトリを「c:\home」のようにあらわすが、日本版では「c:¥home」になるのはナショナル・ユース・ポジションのためである。
そこで各国の公的文字コードを文字化けなしに共存させるための枠組として制定されたのがISO/IEC 2022という文字コード拡張法である。
比喩で説明すると、ISO/IEC 2022はオリンピックの入場行進のようなものである。開会式では、各国選手団は国名を記したプラカードを先頭にかかげて行進するが、ISO/IEC 2022でも文頭や文字コードの変わり目には、どの文字コードで符号化したかをあらわす識別符号列をおいている。
92[16進数の5C]という文字番号(符号)だけでは、どの文字かわからないが、日本のJIS C 6220で符号化したことがわかれば「¥」、ドイツのDIN66083なら 「ö」、アメリカのASCIIなら「\」と一意的に定まるのである。
文字コードの識別符号列は、制御符号のひとつであるエスケープ符号ではじまるので、エスケープ文字列と呼ばれている。ISO加盟国が自国の公的文字コードをISOの国際登録簿(注2)に登録すると、一意的な識別符号列があたえられる。エスケープ文字列によって、符号を解釈する符号表を切り換えるというのが、ISO/IEC 2022のもともとの考え方である。文字コードを切り替え可能にするには、同一の構造をとっていなければならないが、初期のISO/IEC 2022はASCIIの構造を標準とするように定めていた(現在は別規格で規定)。
日本はアルファベットとはまったく異質なカナ文字を符号化するにあたり、ISO/IEC 2022の定めた構造にカタカナを流しこんだ文字コードを作った。これがJIS C 6220(後にJIS X 0201)のカタカナ部分である。JIS C 6220はアルファベットを収録したISO 646(≒ASCII)相当の文字コードと、カタカナの文字コードの二本立てでできている。
アルファベット・コードとカタカナ・コードの切換えはエスケープ文字列ないし制御符号のシフトイン・シフトアウトでおこなうことになっていたが、内部処理にエスケープ文字列をもちこむと処理が複雑になるので、シフトイン・シフトアウトで切り換える実装がほとんどだった。49[16進数の31]はアルファベット・コードなら「1」だが、カタカナ・コードなら「ア」になる。
ISO/IEC 2022は文字コード切り替え以外にさまざまな拡張法が追加され、現在ではかなり複雑化しているが、本稿では漢字情報交換に関係する二つの重要な拡張法を紹介する。
第一に8ビットコードへの拡張である。
コンピュータではデータの基本単位を「バイト」と呼ぶ。コンピュータは8ビットを1バイトとするものが主流となった。ASCIIは一文字を7ビット(0000000〜1111111)であらわす7ビットコードで、余った1ビットを通信の際の誤りチェックに使う方式が一般的だったが、技術の進歩によって、1ビットだけの誤り訂正は意味が薄れ、8ビットをフルに使って文字をあらわそうという考え方が出てきた。
ISO/IEC 2022原案では識別符号によって切り替えることしか想定していなかったが、日本はJIS C 6220のカタカナ部分を128以降に平行移動させ(カタカナの文字番号に128を加算)、8ビット符号の枠内(0〜255)で共存させるようにした。[図2]
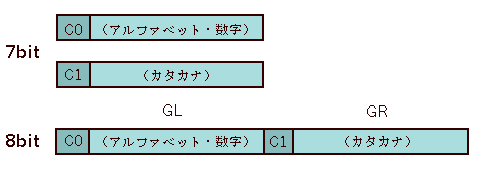 |
7ビット符号では49[16進数の31]が「1」なのか、「ア」なのかは、エスケープ文字列を前方にもどって探し判別しなければならなかったが、「ア」が171[16進数のB1]に移動してくれれば、文字番号(符号)だけで「ア」であることがわかる。
128を加算するというと複雑な処理をしているような印象をもつ人がいるかもしれないが、そうではない。7ビット符号の頭に1をつけて、8ビット符号にするだけでよいのである。たとえば、「ア」をあらわす41は二進数では0110001だが、頭に1をつけて10110001とすると、10進数の177となる(49+128=177)。
JIS C 6220の8ビット拡張はISOによって追認され、ISO/IEC 2022では8ビット符号も使えるようになった。符号表の左に位置する7ビット符号の図形文字領域(33〜126)をGL領域、8ビット符号であらたに加わった符号表の右に位置する図形文字領域(161〜254)をGR領域と呼ぶ(GはGraphic Characterの略)。
第二は多バイト・コードへの拡張である。ISO/IEC 2022では94字の文字を収録できるが、カナ程度ならまだしも、桁違いに字種の多い漢字(常用漢字ですら二千字種におよぶ)はとうていおさまりきらない。そこでISOの文字コード審議に日本代表として出席した和田弘はISO/IEC 2022に多バイトコードへの拡張を盛りこむように強くもとめた。
多バイト・コードとは、一文字を複数バイトの組み合わせであらわす文字コードであり、2バイト・コードなら94×94=8836字を収録することができる。
当時のISOの文字コード委員会参加国はアルファベット文化圏の国々ばかりだったので、大規模拡張の必要性がなかなか理解されなかったが、和田の奮闘によって多バイト化が認められ、ISO/IEC 2022に準拠した漢字コードを開発することが可能になった。
1970年代にはさまざまな漢字処理技術が模索されていたが、ハードウェアも、文字コードも、漢字テレタイプのシステムを流用したものが多かった。もしISO/IEC 2022に多バイト拡張がはいらなかったら、世界最初の公的漢字コードであるJIS C 6226(後にJIS X 0208)は漢字テレタイプ・コードと類似の構造をとったかもしれず、シフトJISなど、JIS変形文字コードも、現在とは違ったものになっていたはずである。次節で述べるように、中国、台湾、韓国、北朝鮮の公的文字コードはJISを手本としており、影響の範囲は日本にとどまらなかっただろう。
インターネットは基本的にISO/IEC 2022の世界である。制御符号領域の符号を含んだファイルをバイナリ・ファイル、改行関係など特定の制御符号と文字符号のみからなるファイルをテキスト・ファイルという。ワープロのファイルは、たとえ文章だけであっても、書式情報や文字修飾情報をあらわすために制御符号領域の符号を流用しているので、バイナリ・ファイルである。
テキスト・ファイルはインターネット上で自由にやりとりできるが、バイナリ・ファイルは制御符号を含んでいるために、中継するコンピュータに異常動作を起こさせる危険性があり、MIMEなどの手法で、データを制御符号領域にかぶらないように変換しておく必要がある。今日、インターネット上で漢字の情報交換ができるのは、和田をはじめとする日本側関係者の努力の賜物なのである。
Copyright 2004 Kato Koiti