加藤弘一
「文字コード問題早わかり」は1996年11月に「カタカナ篇」をかわきりに順次公開し、翌年3月の「ユニコード篇」で一応の完結を見ました。
その後、『電脳社会の日本語』の取材のために関係者に直接お話をうかがったり、関連資料の収集につとめたところ、多くの新事実を発掘するとともに、通説の誤りも見つかりました。本ページにも多くの誤りがありますが、直すとしたらゼロから書き直さなければならないので、内容の更新は1998年5月を最後におこなっていません。
本ページは引きつづき参考として公開をつづけますが、文字コードの歴史に興味のある方は拙著『電脳社会の日本語』(文春新書)をお読みください。(2000年 4月 7日)
手元の英和辞典で codeという単語を引くと、次の五つの意味がのっています。
- 法典。the civil code 民法。
- (団体などの)規約、慣例。the code of the school 学則。
- 暗号、信号。the International Code 万国共通船舶信号、国際電信符号。in code 暗号で、信号で。
- 《電算機》コード、符号。
- 《発生学》(生物の特徴をきめる)情報、暗号。a genetic code 遺伝情報。
「コード」のもともとの意味は、集団の中で決められた約束のことで、それが発展して、集団の中で使われる符丁の意味になっていきました。ある符丁がなにを意味するかは、勝手に決めていいわけですから、その約束を知らない部外者にはなんのことだかわかりません。符丁は暗号としての性格を多かれ少なかれもっています。トンツーであらわされる電信符号は、電信の約束を知らない素人にはまさに暗号です。しかし、約束さえわかってしまえば、符丁の意味するところはあきらかで、いささかの曖昧さもありません。
文字コードについて調べはじめると、次から次へと見なれない言葉が出てきて、問題そのものが暗号でしるされているような印象をうけますが、一つ一つ押さえていけば決して難しくはありません。文字コード問題に王道なしとあきらめて、どうか急がばまわれの精神でおつきあいください。
最近のコンピュータはなかなか頭がよく、英語のつづり間違いを指摘してくれたり、日本語のテニヲハをチェックしてくれたり、やばい表現を警告してくれたりしてくれて、「電脳」という名にふさわしい働きをみせますが、コンピュータは日本語や英語を理解しているわけではなく、内部的には数字の羅列を処理しているにすぎません。
たとえば、
というあいさつは、コンピュータの内部では、
というような2進数(1と 0であらわされる)であらわされた番号の集まりなのです。
今、たとえば、
と間違えてタイプしたとすると、
のようになります。人間の目にはどこがどう変わったのかわかりにくいですが、スペルチェッカーの辞書には最初に示した正しい番号が記録されていますから、それと照合し、2番目の番号「1100001」が間違っているから、「1101010」にしろと教えてくれます(画面の上では、「a」を「e」にしろですが)。
「1100001」が「a」をあらわし、「1101010」が「e」をあらわすというのは、コンピュータを作った人間が勝手に決めたことで、なにも根拠はありません。どの番号がどの文字をあらわすかは約束にすぎないのです。これが文字コードです。文字をあらわす番号のことをコードポイントということもあります。
今、勝手に決めたと書きましたが、コンピュータが誕生してしばらくの間は、メーカーや研究機関が勝手に文字コードを決める時代がつづきました。しかし、めいめいが勝手に決めていると、あるマシンで作成したデータやプログラムを、さん孔テープ(そういう時代だったのです)などで別のマシンにもっていくと、まったく別の数値や文字に変わってしまいます。データのやりとりができないのです。
それでは不便なので、共通の約束を決めようという動きがおこりました。こうして、1962年にアメリカでANSI(日本のJISにあたるアメリカの標準規格)の規格として誕生したのがASCIIコードです。日本にアスキーという会社がありますが、あれはASCIIコードにあやかった命名で、アスキーがASCIIコードを決めたわけではありません(これが下手な冗談でないことは、やがてわかります)。
ASCIIとは、
の略です。
ASCIIコードは、あくまで他のコンピュータと情報交換をするためのコードで、マシン内部でどんなコードを使うかまでは決めていません。ASCIIコードが誕生した1962年は、アタナソフが世界最初の最初のコンピュータであるABCマシンを完成させてから20年以上もたっていましたから、それまでに稼働していたすべてのコンピュータのコードを、ASCIIコードに変えるわけにはいかなかったのです。中ではどんなコードを使ってもかまわないが、データを外へ出す時はASCIIコードでやってくれというわけですね。そこで、ASCIIコードのような情報交換用コードを外部コード、マシン内部で使われる情報処理用コードを内部コードと呼ぶことが多いようです。
ASCIIコードは外部コードとして生まれましたが、あたらしく作られるコンピュータでは、しだいに内部コードとしても使われるようになりました。その方がめんどくさくないからです。
ASCIIコードの特徴は「1100001」のように7桁の2進数(7bit)であらわされていることです。7bitは「0000000」(10進数の 0)から、「1111111」(10進数の 127)までの 128の文字種をあらわすことができます(2の7乗)。
「1100001」という2進数表記はめんどくさいので、原理を説明する時くらいにしか使わず、ほとんどの場合は"4E"とか"6A"のような16進数で表記されます。16進法では10進法の16になるまで桁がくりあがりませんから、10進法の10以上の数を1文字であらわす数字が必要になります。数字は0から9までしかありませんから、10~15の数は"A"~"F"で代用することになりました。"E"や"A"は、アルファベットではなく、数字だということをおぼえておいてください。
2進数の「1100001」は16進数では「61」になりますが、これは10進数の 97にあたります(16 x 6 + 1 = 97)。なお、16進数は10進数と見わけがつかないことがあるので、"6/1"としたり(この場合、a~f ではなく 10~15 を使います)、頭に"0x"をつけて"0x61"としたりしますが、ここでは後ろにhをつけ、"61h"と書いて10進数と区別することにします。16進数はこのあともたくさん出てきますが、単なる数字ですから、怖がらないでください。
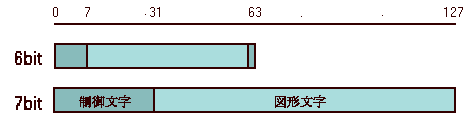
ASCIIコード以前には5bitや6bitの文字コードがあり、ASCIIコードも一時は6bit案が有力だったそうです。5bit(32種の文字)では数字と算術記号と若干の変数用文字、それから「改行」や「BackSpace」、「伝送終了」のような制御文字だけで満杯です。制御文字は普通は画面に表示されませんが、コンピュータや通信の制御という重要な役割をもっていて、コンピュータと対話するには絶対必要です。コントロール・コードとか機能キャラクター、機能文字と呼ばれることもあります。なお、「ABCD...」といった普通の文字は、制御文字に対して、図形文字と呼ばれています。
これでは計算ができるだけですが、コンピュータは電子計算機と呼ばれていたくらいですから、計算ができれば十分だったのです。6bit(64種の文字)なら、大文字だけとはいえ、アルファベット 26文字もはいり、複雑なプログラムが書けるようになります(当時のプログラミング言語は大文字しか使いませんでした!)。
幸いなことに、最終的には将来の拡張性を考慮した7bit案が通りました。7bitにしたおかげで、当初は大文字だけだったアルファベットも、後に小文字がはいり、どうにか英語の文章が書けるようになりました。もっとも、あくまでプログラムを表記する程度のことを念頭において決められた規格ですから、「"」という引用符を一つですましてしまうなど、7bit(128文字種)におさめるために無理をしていて、きちんと英語の正書法にのっとって書けるようにはできていませんでした。
コンピュータの世界は2進法をもとにできていますから、7bitというのはいささか半端な単位です。きりのよい8bit(256種)なら、引用符はもちろん、ヨーロッパの言語で使われるアクセントつき文字やエスツェットなども楽にはいって、好都合だったのですが、7bitのASCIIコードがアメリカの標準として確立してしまいました。まあ、6bitにならなかっただけましですね。
1962年当時はコンピュータ=計算機で、マシンの能力も低かったですから、どうにかプログラムが書ければ上等だったのでしょう。まさかコンピュータで日記を書いたり、小説を書いたりする時代がくるとは夢にも思わなかったはずで、ASCIIコードの設計者を責めるわけにはいきません。
ASCIIコードは 30年以上前に生まれた規格ですが、インターネットの世界などネットワークの世界では今でも主流で、特にアメリカではASCIIコードしかうけつけないサーバーが大半をしめているようです。インターネットでメールを送る場合は、ASCIIコードにしか対応しないサーバーにも中継してもらう可能性があるので、8bitの文字コードは 8桁目を切り捨て、無理やり7bitデータにして送るというようなことをやっています(SMTPプロトコールといいます)。
8桁目を切り捨てれば、文字を表していた番号(コードポイント)が別の番号に変わってしまい、違った文字が表示されてしまいます。そこで、MIME転送などの工夫で、あらかじめ8bitのデータを7bitに変換するというようなことをやるのですが、本題からずれるのでここでは説明をはぶきます。メーラーの設定を間違えると、「B4IM}?M$Ni2,!wKLN&@hCBg3X1!$G$9!#」のような暗号のような文章に化けてしまうことがありますが、こういうトラブルは漢字をASCIIコードに変換する時に生じるくらいは知っておくと、便利でしょう。
ISOとはInternational Organization for Standarization(国際標準化機構)の略称で、アメリカのANSI、日本のJISなどはISOに準拠することになっています。
国際文字コードの審議は ASCIIの誕生した1962年からはじまりましたが、6bit案と7bit案の論争がまたしてもむしかえされました。6bit=64文字種ではヨーロッパの言語はまともに表記できないのですが、当時、人間の使う言語を表記するという発想はなかったのです。日本の和田委員はアメリカの7bit案を支持したのですが、ヨーロッパ諸国が 6bit案を強硬に主張したために議論がまとまらず、ついに 1966年、6bit案と7bit案を併記する Recommendation(勧告)という形で ISO R 646原案が提出されました。
6bit案(下図参照)と7bit案(ASCIIとほぼ同じ)は、制御文字の数や位置がちがうなど、互換性がありません。ISO R 646はまったく異なるコード案を併記した異常な規格だったのです(玉虫色の決着というやつですね)。日本は最終投票で反対票を投じましたが、21ヶ国中17ヶ国が賛成したために、ISO R 646は 1967年12月に国際規格となりました。
以下に 6bit系と 7bit系を対比した概念図と、6bit系のコード表をかかげておきます。とくとご覧ください(笑)。
| 0 | 1 | 2 | 3 | ||
|---|---|---|---|---|---|
| 0 | SP | 0 | NUL | P | |
| 1 | HT | 1 | A | Q | |
| 2 | LF | 2 | B | R | |
| 3 | VT | 3 | C | S | |
| 4 | FF | 4 | D | T | |
| 5 | CR | 5 | E | U | |
| 6 | SO | 6 | F | V | |
| 7 | SI | 7 | G | W | |
| 8 | ( | 8 | H | X | |
| 9 | ) | 9 | I | Y | |
| A | * | : | S | Z | |
| B | + | ; | K | [ | |
| C | , | > | $ | L | £ |
| D | - | = | % | M | ] |
| E | . | < | & | N | ESC |
| F | / | ' | O | DEL | |
インターネットで国際的な情報交換が日常のことになった今日から見ると、6bit案は悪い冗談ですが、1967年の時点ではしかたなかったのでしょう。タイムマシンで 1967年にもどり、ISOの委員に8bitにした方がいいと勧めたとしても、みんな笑って相手にしなかったと思います。
もちろん、コンピュータの進歩は日進月歩ですから、6bit案はすぐに使い物にならなくなり、1973年には 7bit案に一本化され、R(勧告)がとれて ISO 646となりました。
ISO 646はほとんどASCIIコードと同じですが、23hや24h、5Bhから5Ehなど12個の番号(コードポイント)については、各国がお国事情にあわせて独自の文字をわりふってよいことになっています。
英語モードの「c:\home」が、日本語モードでは「c:¥home」になってしまうのは有名ですが、これはASCIIコードで「\」をあらわす"5Ch"(10進数の 92)という番号(コードポイント)に、次にのべるJIS X 0201という日本の文字コードが「¥」をあてていることに原因があります。
モードを変えると、似ても似つかない文字に化けてしまうのは困ったものですが、別にJISが勝手なことをやっているわけではありません。フランスは"5Ch"に「![]() 」を、ドイツは「
」を、ドイツは「![]() 」をあてています。7bit(128文字種)の枠内では、こうせざるをえないのです。
」をあてています。7bit(128文字種)の枠内では、こうせざるをえないのです。
アメリカでASCIIコードを6bitにするか、7bitするかでもめていた頃、日本でも、後にISO委員となる逓信省電気試験所(現在の電総研)の和田弘氏を中心に、JIS規格として文字コードを決めようという研究が進められていました。当時の技術レベルでは漢字は無理にしても、カナ文字ならば十分あつかえたので、ASCIIコードにカナを加えた独自の文字コードを作るメーカーがあらわれていて、一日も早い外部コードの規格化が待たれたのです。
1967年にISO 646が誕生すると、これに準拠するかたちで、1969年に今日いうところのJIS X 0201が制定されました。日本語の名称は「情報交換用符号」です(1997年3月から「7ビット及び8ビットの情報交換用符号化文字集合」に変わります)。なお、もとになった ISO R646が1973年にISO 646に改められたのにともない、JIS X 0201も1976年に改正されました。いつの版かを区別するために、JIS X 0201:1996と改正年度を後ろにつけて表記することもあります。
ややこしいですが、JIS X 0201という名称になったのは1987年からで、それまではJIS C 6220と呼ばれていました。「C」というのは、電気製品の規格をあらわす分類符号で、ちなみに「A」は土木・建築、「B」は一般機械をあらわします。「C」の6000番台にはコンピュータ関係の規格が集められていました。コンピュータは電気製品といえないことはないものの、電線やモーターや電球とはかなり性格を異にしますし、コンピュータ産業が発展するにつれ、多くの規格が必要になってもきました。そこで、またまた泥縄な話ですが、1987年に「情報処理」という分類項目が独立することになり、「X」という分類符号がわりあてられました。「X」の200番台には文字コード関係の規格が集められていますが、X 0201という番号からわかるように、これは日本の文字コードの大元になる規格です。
JIS X 0201には、ISO 2022という約束(「続・漢字篇」でふれます)にしたがってつくられた、7bit系と8bit系という二つの文字コード体系があります。
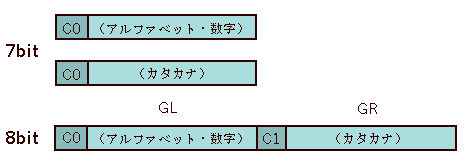
7bit系の方は、128文字種の文字セット二つからなり、最初の文字セットはISO 646そのままですが、二番目の文字セットの制御文字領域の後ろにはカタカナ(次章でのべるJIS X 0208ができると1バイトカナとか、不正確な呼び方ですが、半角カナと呼ばれるようになります)が割り当てられ、この二つの文字集合を制御文字によって切り替えるようになっています。文字集合を切り替える方式をモード切替方式と呼びます。
8bit系の方は、1~128番までに7bit系の最初の文字集合(ISO 646そのもの)、129~256番までに二番目の文字集合を配置しています。ちなみに、最初の文字集合のうちの図形文字部分をGL領域、後の方の図形文字部分をGR領域と呼びます。上図をご覧になればわかるように、左側にならぶ図形文字だからGL(Graphic Left)、右側にならぶ図形文字だからGR(Graphic Right)となるわけですね。
ここでJIS X 0201の8bit系の組立をみておきましょう。
| 範囲 | 文字 | |
|---|---|---|
| 00~1F | 制御文字 | C0 |
| 20~40 | 記号・数字 | GL 領 域 |
| 41~7A | アルファベット | |
| 7B~7F | 記号 | |
| 80~9F | 空き領域 | C1 |
| A0 | 未定義 | GR 領 域 |
| A1~A5 | 句読点 | |
| A6~DD | カタカナ | |
| E0~FF | 空き領域 |
ご覧のように、JIS X 0201の8bit系は、制御文字を別にすると、アルファベット(Alphabet)、数字(Numeric)、カタカナ(Katakana)から構成されています。それぞれの頭文字をとり、ANK文字と呼ぶこともあります。カタカナの前に空き領域が来るのはもったいないように思うかもしれませんが、7bit系との互換性を維持するためには仕方ないのです。
なお、JIS X 0201のカタカナ(1バイトカナ)は 7bitコードしか受けつけないマシンが間にはいるかもしれないネットワーク(インターネットがそうですね)では使ってはいけないことになっています。実際、インターネット上での日本語データ伝送方式についての合意である ISO 2022JP(RFC1468)では 1バイトカナは排除されています。
悪名高いマイクロソフト社の MSIMなど、一部のメーラーでは 1バイトカナが送れてしまいますが、メールの伝送経路や、受け手のシステムによっては異常が起きる可能性があり、最悪の場合、システムがフリーズしてしまいます。インターネット経由でメールを出す場合は、JIS X 0201のカタカナは使わないのが慣行です。一部のメーリングリストやニュース・グループで、うっかり1バイトカナを使おうものなら、罵倒メールが殺到しますが、これは使う方が悪いのです。
「情報交換用符号化文字集合」と称しながら羊頭狗肉もはなはだしいですが、JISの責任というより、ASCIIコードが 7bitのせいなのです。ASCIIコードを設計した人たちは精いっぱい将来性を考慮したのですが、人間の知恵には限界がある以上、仕方がありません(くりかえしますが、1967年の時点では6bit案こそが現実的選択で、将来を考えて7bit符号を選んだのは大きな冒険でした!)。
Copyright 1997 Kato Koiti
This page was created on Nov01 1996; Last updated on Feb12 1997.