加藤弘一
「文字コード問題早わかり」は1996年11月に「カタカナ篇」をかわきりに順次公開し、翌年3月の「ユニコード篇」で一応の完結を見ました。
その後、『電脳社会の日本語』の取材のために関係者に直接お話をうかがったり、関連資料の収集につとめたところ、多くの新事実を発掘するとともに、通説の誤りも見つかりました。本ページにも多くの誤りがありますが、直すとしたらゼロから書き直さなければならないので、内容の更新は1998年5月を最後におこなっていません。
本ページは引きつづき参考として公開をつづけますが、文字コードの歴史に興味のある方は拙著『電脳社会の日本語』(文春新書)をお読みください。(2000年 4月 7日)
今までJISで決めた文字コードの話をしてきましたが、実はほとんどのパソコンで使われている文字コードはJISで決めた文字コードではありません。シフトJISという、JIS X 0208と文字のならび方(区点であらわされる文字の相対位置)は同じだけれども、コードポイント(16進数であらわされる文字の絶対位置)はまったく異なる私製文字コードなのです。もっとも、あまりにも普及し、事実上の標準となってしまったために、1997年3月のJIS X 0208第三次改正でJIS規格にとりいれられることになりましたが。
シフトJISの歴史は1982年にさかのぼります。当時は16bitパソコンの出はじめの時期で、前年の8月にはIBMがIBM PC/XT(DOS/V機の原型となったIBM PC/ATのさらに原型です)を発売しましたし、日本のメーカーも16bitパソコンの準備をはじめていました。
国産の16bitパソコン第一号となったのは三菱電機のMULTI 16でした。シフトJISは、MULTI 16の基本ソフトとプログラミング言語の移植にあたったアスキーマイクロソフト社が考案した文字コードです。
アスキーマイクロソフト社は、日本の初期のパソコン市場をリードしたアスキー社が、アメリカ Microsoft社の極東代理店業務をおこなうために設立した子会社で、Microsoft社の初期の代表的商品だった MS-BASICを国産マシンへ移植する一方、Microsoft社とはライバル関係にあった Digital Research社とも代理店契約を結び、同社のCP/MとCP/M86の移植もおこなっていました。
MULTI 16はMicrosoft社の MS-DOS(英語版)でも動きましたが、もともとはDigital Research社のCP/M86で動かすことを前提にしたマシンで、アスキーマイクロソフト社はMS-BASICの一変種である MBASICを、漢字が使えるように拡張してMULTI 16のCP/M86上に移植しました。これが MBASICplusです。シフトJISはもともとは MBASICplusの内部処理用につくられた文字コードだったのです。
シフトJISはアメリカ製ソフトの日本語化に適していたので、Microsoft社の基本ソフトであるMS-DOS ver2.0漢字版にも採用されました。翌1983年にはアスキー、三菱電機、日本IBM、Microsoft社の4社で協定を結び、パソコンの内部処理用文字コード(内部コード)としてシフトJISを使っていくことを確認しました(MS-Kanjiコードとも呼ばれています)。シフトJISの裏づけは、1997年1月のJIS X 0208改正までは、この4社協定だけでした。
シフトJISは、出発時点では内部コードだったのですが、MS-DOSが16bitパソコンの基本ソフトの標準の地位を確立するにつれ、外部コードとしても使われるようになり、ついにはJISコードを押しのけ、事実上の標準となってしまいました。その現実の遅ればせの追認が、JIS X 0208:1997におけるシフトJISのとりこみなのです。アスキーという社名は、アメリカの標準文字コードであるASCIIコードにあやかったものですが、そのアスキー社が日本の事実上の標準文字コードを生みだすことになったのはなにかのめぐりあわせでしょうか。もちろん、「神童」と呼ばれたアスキー社の創業者、西和彦氏の政治力がものをいったのでしょうが。
西氏の政治力はともかくとして、シフトJISはどんな点がすぐれていたのでしょうか?
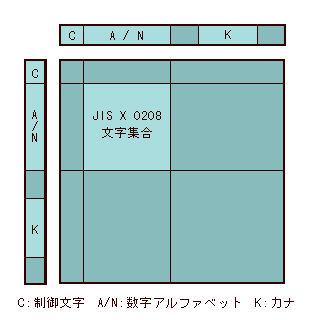
1982年の時点で、JISの文字コードは二つありました。ANK文字(アルファベット、数字、カタカナ)からなるJIS X 0201と、漢字やギリシャ文字、ロシア文字などからなるJIS X 0208です。JIS X 0208は、JIS X 0201といっしょに使う前提でつくられていましたが、いっしょに使うといっても、JIS X 0208は1バイト目も2バイト目も、JIS X 0201のアルファベット・数字部分ともろにぶつかっています。
たとえば、JIS X 0208(7bit系)における「字」という文字の16進表記は"3B7A"ですが、JIS X 0201では"3B"は「;」、"7A"は「z」にあたりますから、"3B7A"は「;z」をあらわします。"3B7A"は「字」でもあれば「;z」でもあるということになるのです。
こうした混乱を整理するための約束がISO 2022です(日本語版はJIS X 0202)。
ISO 2022は複雑で難解な規格なので、譬え話で説明しましょう。四つの楽屋(G0、G1、G2、G3と呼ばれる)のある大劇場を思い浮かべてください。この劇場にはアメリカのASCII劇団や、ヨーロッパ系のISO 8859-1劇団、日本のJIS X 0201劇団、JIS X 0208劇団、中国のGB 2312劇団、韓国のKS C 5601劇団など、ISOに登録されている世界中のさまざまな劇団(文字コード)が集まってきていると思ってください。役者にあたるのは文字です。
ANK文字のJIS X 0201劇団を舞台に出すには、まず劇団にG0楽屋にはいるよう指示しておき、それから「G0楽屋さん、出番ですよ」と呼びだすようにします。漢字のJIS X 0208劇団を舞台に出すには、同様にG1楽屋にはいるよう指示しておき、「G1楽屋さん、出番ですよ」と呼びだします。そうすると、漢字という役者が舞台に登場するわけです。今、舞台に出ているのはどの劇団かということをはっきりさせておけば、たとえハムレットやオフィーリアがたくさんいたとしても、混乱することはありません。
このような指示と呼び出しという二段構えで複数の文字コード(劇団)を仕切ろうというのがISO 2022の発想です(うるさいことを言えば、JIS X 0208が使っているのは、ISO 2022そのものではなく、ISO 2022-JPという楽屋の数を2つだけにした簡易版ですが)。
たとえば「Shakespeareは1564年に生まれた。」という文を例にとると、
Shakespeare (0208呼びだし) は (0201呼びだし) 1564 (0208呼びだし) 年に生まれた。
というように、エスケープシークエンスという黒衣が、見えないところで、舞台に出ている劇団をいれかえているのです。
めんどくさく見えるかもしれませんが(実際、めんどくさいのですが)、こういう仕組をつくることで、それぞれの劇団(文字コード)の固有性をたもったまま、同じ舞台に乗せることができます。日本のUNIXユーザーのグループは、Muleという世界中の言葉を同時にあつかうことのできるエディタをつくりあげましたが、Muleの多国語環境はISO 2022によって実現されています。
それに対してシフトJISは、日本の劇場なんだから日本の二つの劇団しか出演しないだろうと割りきり、JIS X 0201劇団の役者(文字)とJIS X 0208劇団と役者をごちゃまぜにした統合劇団をつくり、一つの大部屋にまとめて一元的に管理しようというものです。
下の図をご覧になればおわかりのように、JIS X 0201のアルファベット・数字部分とカナ部分の間(80~A0)、それからカナ部分のうしろ(E0~FF)に、文字の割り当てられていない空き番号が65個あります。この空き番号を漢字の1バイト目に使うのがシフトJISです。
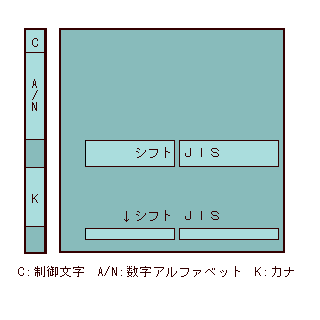
実際は65個すべてを使うのではなく、"81~9F"の31個と"E0~EF"の16個の合計47個で、"81~9F"ないし"E0~EF"の範囲の番号があらわれたら、次にくる番号とあわせ、2つで1つの文字(2バイト文字)と解釈するわけです。これなら、JIS 0201の1バイト文字と、漢字をあらわす2バイト文字をごっちゃにしても大丈夫ですね。
しかも、なんという偶然でしょうか、この47個の空き番号を第1バイトとして、2バイト目は、制御文字領域とCP/M(およびCP/Mと互換をとったMS-DOS)で使うFD~FFを避けた"40~7E"と"80~FC"の188個の番号を使えば、47 x 188 = 8836となり、JIS X 0208の最大収用文字数 8836字(94 x 94)がちょうどおさまるのです!
ISO 2022下では、JIS X 0201という1バイト文字の劇団に属する役者と、JIS X 0208という2バイト文字の劇団に属する文字とは、別の楽屋にいれられ、舞台に呼びだされるのも別でした。ところが、シフトJISでは一つの大部屋にいれられます。「日本の文字はみな兄弟」というわけですね。MS-DOS上のアメリカ製ソフトはISO 2022のような複雑な仕組は考慮していなかったので、「日本の文字はみな兄弟」のシフトJISは都合がよかったのです。
しかし、「日本の文字はみな兄弟」とは、裏返せば「日本以外の文字はみな排除」ということでもあります。限られた範囲の文字については平等にあつかうが、範囲外の文字は排除するというのがシフトJISの思想です。
ISO 2022にしたがっていれば、劇団ごとに楽屋を分離するという仕組のおかげで、中国や韓国の文字も、アクサンやウムラウトをふくんだヨーロッパ系の文字も、同じ舞台に立てたのですが、シフトJISでは、一つしかない楽屋は日本の役者(文字)でいっぱいですから、中国語や韓国語、フランス語、ドイツ語等々の役者(文字)を受けいれる余地はありません。
外国の文字だけではありません。後に述べるJIS X 0212劇団という第三の劇団(JIS補助漢字)が1990年に結成されましたが、シフトJISの大部屋はすでに満杯だったために、補助漢字劇団の役者は仲間外れにされ、ずっと出番があたえられないという状況がつづいているのです。
ISO 2022か、それに近い仕組を使えば、シフトJISと補助漢字を共存させることも可能ですが、そんなことをしたら「限られた範囲の文字を平等にあつかう」というシフトJISの唯一の利点が失われてしまいます。それなら、わざわざシフトJISを使う必要はなく、はじめからISO 2022準拠のJISコードを使えばよかったでしょう。
シフトJISの問題点はほかにもあります。前章でJIS X 0201のカナ部分は8bit目(16進数の80からFFまで、10進数の128から255までの番号)を使うので、7bitのASCIIコードを基本とするインターネットのメールでは問題がでてくると書きましたが、8bit目を使うのはシフトJISも同じです。最近はMIME転送といって、問題がおきないような工夫がされていますが、できるだけ使わないですませた方がいいでしょう。
謹 告
この章の部分字形統一をめぐる記述に関し、JCS委員会の豊島正之様から内容に誤解があるとご指摘をうけました。すぐには資料を調べにいけないので、一時、公開停止として、9月15日を目処に、この件に関する見解のページとともに再公開する予定と書きましたが、その後、豊島様のメールを詳しく拝見した結果、付記をつけた上で、公開を再開することにしました。ご面倒でも付記をご覧ください。(Aug19 1997)
JISは工業規格ですから、技術の進歩にあわせて、5年ごとに見直しをすることになっています。シフトJISの使用を確認した四社協定が結ばれた1983年、JIS X 0208の最初の改正がおこなわれます。
普通、改正がおこなわれると、旧来の規格は廃止されるのですが、JIS X 0208の場合、改正前の第1次規格(旧JISとか78JISと呼ばれます)と、改正後の第2次規格(新JISとか83JISと呼ばれます)が並立しているように言われていた時期がありました。JISの立場からいえば、最新の規格しかないはずなのですが、二つの規格があるかのように言われたのには理由があります。
83年改正では、実に299の文字種について字形変更がおこなわれました(後にふれる野村論文では294字について字形変更したとありますが、97年改正のJCS委員会が調査したところ、実際には299字が変更されていたとのことです)。字形変更とは字形の簡略化です。「![]() 」を「鴎」、「手國」を「掴」、「眞頁」を「顛」とするような、一部で使われていた極端に簡略化された字形が採用されました。
」を「鴎」、「手國」を「掴」、「眞頁」を「顛」とするような、一部で使われていた極端に簡略化された字形が採用されました。
こうした簡略字形は、学生のノートなどプライベートな場面でで使われてきたもので、左翼グループの立看やビラ(機動隊の「機」を「木キ」と書きました)を別にすると、公の場所で使われることはありませんでした。ところが、朝日新聞は1950年代から簡略字形を積極的に採用し、読者や執筆者の抗議にもかかわらず、1980年代までは漢字改革の急先鋒をつとめました(最近はなし崩し的に一般的な字体をとりいれているようです)。朝日新聞の文字簡略化は徹底していて、97年改正のJCS委員会の調査によると、JIS X 0208の6355字中、2000字以上の文字種で簡略化をおこなっていました。朝日新聞の字形は、他の活字デザインとかけはなれているので、文字コード問題の研究者の間では、特に朝日文字と呼ばれているそうです。
字形の簡略化と同時に、正字体と新字体の両方が収録されている22組の漢字については、水準間の字体いれかえが強行されました。旧JISでは「壺」が第1水準、「壷」が第2水準だったのですが、新JISでは「壷」が第1水準、「壺」が第2水準になりました。「檜」と「桧」、「籠」と「篭」、「頸」と「頚」、「鶯」と「鴬」、「灌」と「潅」も同じです。
水準間で字体をいれかえたために、旧JISのマシンで「壺」と書いた文書を、新JISのマシンに読みこむと「壷」に変わってしまいます。逆に「壷」は、「壺」に化けます。「壺」が「壷」になり、「壷」が「壺」になるというのも困りますが、人名では問題は深刻です。「檜山」さんが知らないうちに「桧山」さんになり、「桧山」さんが「檜山さん」になってしまうのですから、困った話です。法律問題にだってなりかねません。
また、83年当時は半導体の製造技術が未発達で、一部のハイエンドの機種をのぞけば、標準でついているのは第1水準漢字ROMだけで、第2水準漢字ROMは高価な別売部品でした(印刷するためには、プリンタの方にも第2水準漢字ROMが必要でした)。このような状況下で、「壺」と「壷」、「檜」と「桧」、「籠」と「篭」、「頸」と「頚」を水準間でいれかえることは、「壺」ではなく「壷」、「檜」ではなく「桧」、「籠」ではなく「篭」、「頸」ではなく「頚」を使うよう、ユーザーを誘導する効果を生みました。第2水準漢字が標準で使えるようになるのは、1986年以降を待たなければなりませんでしたから、別売部品を買わなければ、使いたい字が使えないという状態が数年にわたってつづいたのです。
使いたい字が使えないだけではなく、意図した文字と違ってしまうのですから、ユーザーだけではなく、メーカーも迷惑しました。原因はJISの側にあっても、ユーザーはメーカーに苦情を言ってきます。過去に作成したデータの継続性を保証しないと、ユーザーが怒るのは当たり前ですし、別のメーカーの製品に乗り換えるかもしれません。メーカーにしてみれば、字体いれかえはもとより、字形変更も絶対にやってほしくはなかったのです。
多くのメーカーはすぐには新JISをうけいれませんでした。新JISを一応うけいれても、OASYSのように、旧JISまじりの折衷文字セットを使う機種もありました。パソコンではガリバー型寡占(シェアは7割を越えていました)といわれたNECの98シリーズが、1992年に登場する9821シリーズまで、実に10年にわたって旧JIS(正確に言えば、旧JISならびのシフトJIS)を使いつづけました(Windows3.1が普及したので、がんばれなくなったというのが切替の理由でしょうね)。ガリバーがそっぽを向いたのですから、事態は深刻です。
南北朝の動乱ではありませんが、新・旧JISが並立するという異常事態が、10年間もつづいたのです。旧JISマシンはいまでも一部で現役ですから、15年以上つづいているといっても過言ではないかもしれません。
もしJISに強制力があり、すべての製品が一斉に新JISに移行したのなら、過去に作成したデータが化けるだけですんだのですが(それだけでも大問題ですが)、新・旧JISが勢力伯仲したまま、10年にわたって並立したために、互換性問題が生じました。9801シリーズだけを使っていても、プリンタによっては新JIS採用の機種があったので(NECブランドのプリンタにも新JIS機がありました)、画面の文字と違う文字が印字されるというトラブルがおきました。また、9801互換機を称していたエプソンのパソコンは、新旧JISが混在した奇々怪々文字セットを採用していたために、二つのマシンが混在する職場でデータをもちはこぶと、「檜山」さんが「桧山」さんになり、「桧山」さんが「檜山さん」になるという混乱もおきました。
9801で書いた原稿をフロッピー入稿すると、「壺」と書いたはずが、ゲラでは「壷」になっていたなんていうことは日常茶飯事でしたが、ゲラなら本人が確認できるので実害はありません。深刻なのは、パソコン通信などネットワークでデータを送る場合です。向こう側のコンピュータに「檜山」と表示されているか「桧山」と表示されているか、「壺井」になっているのか「壷井」になっているのかは、書いた本人には確認のしようがないのです(怖いですよね)。
あえて83年改正を弁護すれば、新JISと旧JISは別の文字集合としてISOに登録されたので、ISO 2022に準拠したシステムなら、理論上、使いわけることが可能だったということがあります。ただし、あくまで理論上です。当時は半導体製造技術が未発達だったので、第2水準漢字ROMさえ別売という状態で、7000字近い文字集合を二つももったマシンなど、皆無に近かったからです。また、シフトJISが普及してしまったために、半導体が安くなっても、文字集合の使いわけが不可能になるという不幸も重なりました。
83年改正の委員会は、なぜ、こんな迷惑千万な「改正」をやらかしたのでしょうか? 「改正」しなければならない必然性とは、どんなものだったのでしょうか?
1983年の JIS X 0208(正確には JIS C 6226-1983)の付属文書には、漢字に関する改正は1981年に公示された常用漢字表および新人名用漢字別表にあわせるためだと書いてあります。
常用漢字等では、新字体を第1水準に、旧字体を第2水準におく。また、常用漢字等以外の文字及びこれに準じた関係とみなされるものは、同様に扱う。
規格表の定義によれば、「常用漢字等」とは常用漢字表と新人名用漢字別表のことです。どちらも内閣告示にもとづくものですから、一見、正論のように思えます。しかし、よくよく調べてみると、「常用漢字等」に根拠のある字体いれかえは、一組もありませんでした。なにしろ「檜」・「桧」も、「壺」・「壷」も、「濤」・「涛」も、常用漢字表にははいっていないのですから。
字形変更についても、常用漢字表にもとづく変更は14字、新人名用漢字別表にもとづく変更は16字にすぎません。内閣告示を根拠とした変更は、299の字形変更のうち、わずか一割でした。「![]() 」が「鴎」になったのも、常用漢字表のせいではありません。常用漢字表には、「
」が「鴎」になったのも、常用漢字表のせいではありません。常用漢字表には、「![]() 」も「鴎」もはいっていないのです。
」も「鴎」もはいっていないのです。
なぜ字形変更と字体いれかえをやったかというと、部分字形の統一という83年改正の委員会がうちだした独特の主張を実現するためでした。部分字形とは、偏や旁のことのようです。「![]() 」そのものは常用漢字表にありませんが、「欧」や「殴」が常用漢字表にあるので、「区」という偏の形状(部分字形)をそろえるために「鴎」にしたわけです。規格票では、これを「部分字形の統一」と称しています。
」そのものは常用漢字表にありませんが、「欧」や「殴」が常用漢字表にあるので、「区」という偏の形状(部分字形)をそろえるために「鴎」にしたわけです。規格票では、これを「部分字形の統一」と称しています。
字体いれかえも同じ論理でおこなわれました。「桧」も「檜」も常用漢字表にはありませんが、「会」という字が常用漢字表にはいっていることを根拠に、第2水準だった「桧」を第1水準に、第1水準だった「檜」を第2水準に移動させたのです。「壺」と「壷」も、「亜」が常用漢字表にはいっていることを根拠に、「壷」を第1水準、「壺」を第2水準に変更しました。
しかし、部分字形の統一をしろなどという原則は、常用漢字表にも、常用漢字表のもとになった国語審議会の答申にも書かれていません。いや、書かれていないどころか、常用漢字表の前書きには、次のような一文があるのです。
常用漢字表に掲げていない漢字の字体に対して、新たに、表内の漢字の字体に準じた整理を及ぼすかどうかの問題については、当面、特定の方向を示さず、各分野における慎重な検討にまつことにした。
国語審議会は、部分字形の統一という性急な主張に、待ったをかけていたのです! 83年改正をおこなった第2次JCS委員会は、国語審議会の決めた方針を無視して、部分字形の統一を勝手に強行したわけです。
ここで、敗戦後の国語政策についてふりかえっておきましょう。
常用漢字表が1981年に公布される以前は、当用漢字表が、35年間にわたって施行されていました。当用漢字表は敗戦の混乱に乗じ、1946年に内閣告示・内閣訓令として公布された1850字からなる漢字表で、法令・公文書・教育等で使ってよい漢字の「範囲」を定めていました。まえがきで「漢字の制限」をうたい、専門分野の用語であっても、表の範囲で表記できるよう変更をもとめるなど、杓子定規なしろもので、各方面から批判があいついでいました。
特に顰蹙をかったのは、熟語の一方が表外字の場合、漢字と仮名の混ぜ書きがもとめられたことです。かつての新聞には「一家は誘かい犯の恐かつにがん強にたえた」というような意味不明の表記が踊っていたものです。「犬」がはいっているのに、「猫」がはいっていない点も、おもしろいですね。
国語審議会は1966年から、当用漢字表の害悪をどう是正するかを審議していましたが、1981年に常用漢字表をあらたに公布するという答申を出しました。当用漢字表を改訂するのではなく廃止し、新しい漢字表を制定するということからもあきらかなように、この二つの漢字表は性格がまったく異なります。常用漢字表は漢字を使う上での「目安」をしめすにすぎないのです。
常用漢字表は字数的には95字増えただけですが、あらゆる分野を規制しようとした当用漢字表とは異なり、専門分野や個人の表現までは対象としないこと、固有名詞や過去の文献の漢字使用を尊重することを明記しています。常用漢字表の施行は、漢字使用における規制緩和だったのです。ところが、JISでは逆に漢字制限が強化されてしまいました。
なお、JCS委員会幹事の豊島正之委員は、1997年2月に開かれた文化庁主催「国語施策懇談会」の予稿集に寄せた原稿において、「第2次規格が採用した新字体の類推適用は、当時の国語審議会が当用漢字字体表の表外字への類推適用を企図していた事に基づくもので、第1次規格委員会の議事もその様に進行している」と述べられています。「新字体の類推適用」とは、部分字形の統一をふくむ表外文字の字形変更のことです。83年改正の混乱は、国語審議会の責任だと豊島委員は断定されているのです。
豊島委員が根拠としているのは、第1次JCS委員会の1977年1月28日の会議で、文化庁から参加した石田正一郎委員がおこなった次の発言です。
委員会長(森口繁一) 石田委員によれば字体の略し方にも検討が及ぶことがありうるとのことであったが。
石田正一郎委員 現在の[国語]審議会の雰囲気では、そのとおりである。今後新字体が出されれば、JISでは補正をする含みでいてほしい。
当用漢字表は漢字制限のための表だったので、表の範囲外の漢字は無視していたが、常用漢字表は「目安」を示すものになったので、表外文字も規制されるという論理のようです。
しかし、この発言があったのは83年改正の6年も前の1977年1月です。しかも、83年改正時の委員会での発言ではなく、78年制定時の委員会での発言です。JIS原案委員会は、JIS規格の施行と同時に解散することになっていますから、78年の委員会と83年の委員会は別個の委員会のはずです。
しかも、先に引用したように、1981年に内閣告示として制定された常用漢字表の前書きには、表外文字の字形統一については、「各分野における慎重な検討にまつことにした」と明記してあります。内閣告示の文言をさしおいて、6年も前に一民間機関(日本規格協会)の設置したワーキング・グループ(JCS委員会)の会合で、文化庁の一課長が語った「雰囲気」などという曖昧なものを根拠に、国語審議会に責任があるとした断定は不可解というほかはありません。
さて、83年改正の実務を、事実上、一人でおこなったといわれる国立国語研究所日本語部長(当時)の野村雅昭氏は、JISのPR誌、「標準化ジャーナル」1984年3月号で、JCS委員会を代表し、改正の背景を解説していますが、それによれば、部分字形の統一というJIS独自の原則は、利用者の「誤解」をさけるために必要だったのだそうです。
JIS C 6226(JIS X 0208の旧名)は、文字概念と符号との対応関係を規定したものであり、その関係に変化が生じない限り、その印刷字形を変形する必要はないといってよい。そのような観点からすれば、今回の改正で変更が必要なのは、常用漢字等の政令による漢字に関するもの及び異体字の位置の変更に関するもので十分である。それにもかかわらず、299字について、その字形を変更したのはJIS C 6226の性格について、利用者の理解が十分ではないこと及びJIS C 6234の制定により、その誤解がいっそう高まるおそれがあることによる。
JIS C 6234は、JIS X 0208の83年改正と同時に施行された「ドットプリンタ用24ドット字形」の規格で、現在の名称をJIS X 9052といいます(ここでは、引用以外は、JIS X 9052で通します)。24ドットとは、一つの文字を 24 x 24の点の集まりで表現することで、当時のプリンタは24ドットのフォント(字形データ)を使うのが一般的でした。画面表示の方は16ドットが一般的で、この翌年、「表示装置用16ドット字形」の規格(JIS X 9051)が制定されます(野村氏はJIS X 9052とJIS X 9051の制定でも中心的な役割をはたしたといわれています)。
JIS規格票における「利用者」とは、個々のユーザーのことではなく、メーカーの技術者のことですが(JISは日本工業規格なのです)、では、野村氏の言う利用者の「誤解」とはなんでしょうか? 技術者がどんな誤解をするというのでしょうか?
JIS X 0208の規格票本文の第一項には、つぎのようなただし書きがついています。
この規格は、文字の種類とその符号を規定したもので、その他個々の文字の具体的字形設計等のことは、この規格の適用範囲としない。
付属文書の方には、字形は「書体、機械装置、デザイン」でさまざまに異なるとあります。同じ「字」という文字でも、明朝体の「字」とゴチック体の「字」では字形が違ってきますし、同じ明朝体でも、メーカーによって丸味をおびたデザインもあれば、角ばったデザインもあるでしょう。また、コンピュータの宿命として、ハードウェアの進歩によっても、字形にゆれが生じます。16ドットの段階では、画数の多い文字は細部まで表現しきれませんし、24ドットでも困難な文字があります。しかし、48ドットなら、ほぼ表現しきれます。
こうした事情を考慮し、JIS X 0208は「字形の詳細は定めない」と、あらかじめ断っています。付属の漢字表に印刷されている文字はあくまで例示にすぎず、多少のゆれがあってもよいというのです。ハードウェアが未熟なうちに、その制約内で表現できるよう、字形を細部まできっちり決定してしまっては、将来の進歩したハードウェアの性能を生かすことができませんから、「字形の詳細」を定めないという方針は、工業規格として正当といえるでしょう。実際、印字精度は24ドットから32ドット、48ドット、さらにはアウトラインフォントとどんどん向上していき、字形の美しさはワープロ専用機の重要なセールスポイントになりました。
ところが、メーカーの技術者の間には、ゆれを認める点について不満があったようです。NECの関連会社で、プリンタのフォント製作を長らく担当していた伊藤英俊氏は、『漢字文化とコンピュータ』(中公PC新書)で、次のように書いています。
第1次規格には、「付属書の漢字表は株式会社写研の厚意によって版下作成され……」云々と説明されているが、たまたま同一活字セットに文字がなくて別の活字セットの文字を混用したためなのか、同じ偏や旁をもつ別々の漢字同士で異なった偏・旁で印刷されている文字がある。
このような文字に対して、片方のいずれかの字体に統一するようフォントをつくればよいのか、あるいはそのようなことは気にしなくてもよいのかというようなことまでもメーカーとしては迷うものなのである。
文系の素養に自信のない理系技術者にすれば、頭を使わないですむように、「字形の詳細」までJISでかっちり標準化してほしいということでしょうか。実際、JIS X 0208の例示字形に、一点一画まで、忠実にしたがっていれば間違いないと考える人たちもいたようです。こういう要望があるところに、24ドット・フォントの規格(JIS X 9052)があらたに登場したら、JIS X 9052で決められた字形にしたがうべきか、JIS X 0208の例示字形にしたがうべきかでまたまた混乱がおこるというわけです。
83年改正のJCS委員会は、JIS X 0208で符号化しているのは無形の「文字概念」であり、「その文字概念に基づいてどのような字形が設計されても、そこには矛盾は存在しない」としています。一口にいえば、文字の形なんかどうでもいいんだという立場ですね。この伝でいけば「檜」と「桧」、「壺」と「壷」の違いも、単なる「字形」の違いすぎなくなります。「檜」と「桧」、「壺」と「壷」のいれかえも、「字形」変更の延長でおこなわれたわけです。
百歩ゆずって、「字体」=「字形」だとしても、JIS X 0208の例示字形が、JIS X 9052で標準化された24ドット字形とはまったく性格の異なるものだということは言えるでしょう(前者は単なる例示ですが、後者は規格の本体をなしています)。そうであれば、JIS X 0208での字形が、例示にすぎないことを周知徹底すべきだったのですが、83年改正は逆のことをやりました。JIS X 0208の例示字形を、JIS X 9052の24ドット・フォントにあわせて変更してしまったのです。
そんなことをすれば、JIS X 0208の付属漢字表の例示字形は、JISの規定する標準字形という意味合いをおびてしまいます。字形の細部のゆれを許容するというJIS X 0208の基本的な方針についても、誤解を解消するどころか、助長する結果をまねくでしょう。
特に見過ごしにできないのは、83年当時の技術水準にあわせて簡略化した24ドットの字形を規格中にとりこみ、大量のウソ字をJIS標準であるかのように誤解させてしまった点です。故意なのか、無能の結果なのかはわかりませんが、これは重大な過誤であり、文化破壊です。
こういう「改正」の中心となった野村氏とは、どういう人物だったのでしょうか?
1981年の当用漢字表の廃止と、それにかわる常用漢字表の告示が、漢字使用における規制緩和だということは先に指摘しましたが、この件に関し、野村氏は『漢字の未来』(筑摩書房、1988年)という著書の「表現の民主化と反動」と題した一節に、次のように書いています。
つまり、多少好意的に解釈しても、常用漢字表はせまくかぎられた一般生活という場所におしこめられてしまったわけである。もはや、すべての国民がおなじ文字を所有し、なるべくおなじことばで意志を交換するという理想は、うしなわれてしまった。敗戦後の自由をあれほど享受したわれわれが、こういう事態をまねいたのは、みずからの怠慢によるものである。一九八一年をさかいとして、国語改革における時計のハリは、あきらかに逆にまわりはじめたのである。
常用漢字表が「せまくかぎられた一般生活という場所」におしこめられ云々というのは、当用漢字表が学術的な専門用語をも規制の対象としていたのに対し、常用漢字表は、専門用語や芸術的な表現は対象外と明記したことをさしています。野村氏は、学者や芸術家が一般庶民のわからない難解な漢字を使うのは、民主国家日本にあるべからざることだと批判します。
当用漢字表による漢字制限には多くの行きすぎがあり、廃止すべきだという方針は、1974年から1981年にわたる国語審議会の長期の審議によって出された結論なのですが、野村氏は国語審議会のこの答申は誤りであり、国語改革の輝かしい成果を封建反動勢力に売りわたすものだと弾劾しているのです。
野村氏はこうも主張しています。
当用漢字表による漢字制限が失策だったとするひとは、すくなくない。その論拠は、漢字使用を一定範囲にとどめようとしながら、それに成功しなかったということにつきる。しかし、そのような批判は、当用漢字表の理念を一面からしかみていない、ものいいである。なぜならば、当用漢字表は、漢字制限をめざしてはいたが、徹底した制限そのものではなく、そのための第一歩だったということを、批判者たちはみのがしている。……
漢字制限の推進者たちに、過失があったとすれば、それは制限をもっと効果的におこなうための努力をおこたったことにある。
漢字を簡単にすれば民主化するという主張が、いわゆる戦後派知識人の感傷にすぎないことは、大陸中国と台湾の現在の姿を見ればあきらかです。台湾は封建的な繁体字を使いつづけましたが、みごとに民主化し、公正な選挙によって元首を選出しました。一方、大陸中国は、日本の国語改革以上に過激な漢字改革を断行しましたが、いまだに一党独裁の専制体制がつづき、言論の自由どころではありません。文化大革命期には、簡体字をさらに簡略化した奇怪な文字が氾濫しましたが、人々の心はすさみ、つるしあげやリンチ、公開処刑、文化財の破壊が全国的におこなわれ、一部地域では人肉嗜食まで横行していたそうです。
野村氏によれば、「ヒラガナのなかに漢字がうかんでいる、ふだんみなれた紙面も、よくみつめると、醜悪なもの」だそうで、初等教育をローマ字表記を本則としておこなうようにすれば、「ある時点で、漢字カナまじり文は、なだれをうって、ローマ字表記化」し、理想の民主国家が実現するということです(笑)。
これだけ複雑化した現代社会では、「すべての国民がおなじ文字を所有」するという「理想」は、現実ばなれした空論といわざるをえません。むしろ、漢字の造語力のおかげで、専門用語の意味するところが、門外漢にも漠然とながらわかるという効用の方が重要でしょう。「文字コード」は「Moji Kodo」と書いたらいよいよわからなくなりますが、「文字符号」と書けば、文字をコンピュータで処理できるように符号化するんだなということが、素人にもなんとなくわかります。なんとなくでもわかるということは、専門分野がタコ壺化している現代においては、とても重要なことだと思うのですが、野村氏にいわせれば、封建主義者のたわごとということになるのでしょうか。
一部に、JISの漢字のあつかいが滅茶苦茶なのは、文系の素養のない理系技術者が文字コードを決めたせいだという説がありますが、これはまったくの誤解です。もし、理系の技術者が決めたのなら、専門外の分野について、83年改正のような思いきった改造はできなかったでしょう。あのような紅衛兵ばりの「改正」が断行できたのは、漢字撲滅こそ民主日本の進むべき道と固く信じる「専門家」の確信犯的信念があったればこそです。
野村氏は1981年の当用漢字表廃止に悲憤慷慨し、保守反動勢力の巣窟と化した国語審議会の暴挙にたった一人で立ち向かい、「国語改革における時計のハリ」を前に進めようとしたようです。もちろん、その動機は明るい民主日本を建設しようという美しい信念にありました(笑)。しかし、83年のJIS X 0208の「改正」強行で、野村氏の崇高な願い通り、時計のハリは前に進んだのでしょうか。
JIS X 0208の最初の改正は1983年でしたから、次の改正は1988年におこなわれるはずでした。しかし、実際には1990年にもちこされました。JIS X 0208の改正と同時に施行されることになっていた「情報交換用漢字符号──補助漢字」(JIS X 0212)の制定に手間取ったからです。
補助漢字施行までにはさまざまな曲折がありました。補助漢字はもともと、JIS X 0208の文字種を増やしてほしいという印刷業界の強い要望をうけて、検討のはじまった規格です。JIS X 0208の第1次規格が制定された1978年は、日本語ワープロ第一号機が誕生した年でもあります。初期のマシンはたいして実用にならなかったようですが、コンピュータの進歩は急速で、83年改正の頃にはワープロ専用機が普及し、印刷現場にも導入されるようになっていました。原稿のファイル入稿も一部でははじまっていました。コンピュータで漢字があつかえること自体が驚きだった時代はおわり、文字が足りないという現実がにわかにクローズアップされてきたのです。
文字セットにはいっていない文字は外字として処理しますが、印刷現場では、漢字の外字は使い捨てが普通だったといいます。記号などの外字は他の印刷物で使う可能性が高いので使い回しがききますが、漢字の外字はくりかえし使う可能性が低く、保存しておいても後で探すのが大変でしたから、新しくつくった方が効率がよかったのです。
しかし、外字をつぎつぎとつくるという作業は、大手はともかく、中小の印刷会社にとっては大変な負担でした。文字の不足は中小の印刷業者にとっては切実な問題であり、社団法人日本印刷産業連合会を中心に、通産省に強い働きかけがおこなわれました。
こうした動きを背景に、JIS規格制定作業の実務にあたる日本規格協会は、通産省の依託をうけ、1985年にアンケート調査を実施しました。その結果、51.4%の利用者が文字の追加を望んでいること、しかし、追加を望まない利用者も39.1%いることが判明しました(先に書いたように、JISでいう「利用者」とは一般ユーザーのことではありません)。
翌1986年、日本規格協会は報道機関やデータベース・サービス会社、地方自治体、NTT、コンピュータ・メーカーなどから漢字表を収集して不足文字種をリストアップしていきました。日本印刷産業連合会の方では、印刷現場にはいっている数社の電算写植システムや、印刷会社独自の外字セット、古典文学のデータベース化にとりくんでいる国立国文学資料館の外字セットを収集し、追加要望文字種のデータをまとめました。この二つの調査結果をつきあわせた結果、6万字近い漢字がリストアップされました。そのうち、異なる漢字と認定されたのは諸橋大漢和にのっている文字が12905字、のっていない文字が3247字でした。
この1万6千字余の文字のうち、諸橋大漢和にのっている文字は二つ以上の漢字表にのっているものを残し、のっていない文字については、日本印刷産業連合会と日本規格協会の調査データの両方にはいっていて、しかも三つ以上の漢字表にのっているものを残したということです。以上の作業により、追加する文字種は6千字程度にしぼりこまれました。
JIS X 0208の収録漢字数に匹敵する文字種を追加するわけですから、どういうあつかいにするかをめぐって議論がわかれました。JIS X 0208を拡張するのか、別規格とするのか、参考規格にとどめるのか、JIS外の規格とするのか、さまざまな案が検討されたということです。
結局、別規格案が通るのですが、JIS X 0212の付属文書は決定の経緯を次のように説明しています。
前述のように候補となった文字集合が、JIS X 0208と同じ頻度で使用されるものではないこと、これが規格になったとき、それをシステムに適用する場合には価格や操作性への影響も考えられること、などの理由からJIS X 0208と独立の別規格にすることが適当であるとの結論に至った。すなわち、JIS X 0208で規定されていない文字種を必要とする利用者が、JIS X 0208の補助として使用する文字集合という位置付けにすることになった。
これが「補助漢字」という名称の由来なのですが、実際は「JIS X 0208の補助」という性格が確定するまでには、JCS委員会内部でかなりの暗闘があったようです。
というのも、JIS X 0212は、制定直前まで「JIS第3水準」という名称でアナウンスされていましたし(パソコン用語事典などには、今でもJIS X 0212を「JIS第3水準」と呼んでいるものがあります)、JIS X 0212規格票巻末の委員の一覧をみればわかりますが、なんと委員長が二人いたのです。
この不可解な背景事情にメスをいれた報道に、「しにか」1990年2月号にのった松尾博志氏の「漢字の行政を追う」という記事があります。
松尾氏によれば、通産省は印刷業界からのつきあげで、JISの文字種を大幅に増やすことにしたが、文部省が敗戦後、営々とすすめてきた漢字制限政策に抵触する可能性がでてきたので、文部省の顔を立てるために、文部省傘下で、漢字制限政策の一翼をになってきた国立国語研究所の幹部をJCS委員会の委員長にすえたというのです(JISコードの委員長はそれまではずっとコンピュータ畑の大物学者で、実務を担当する国語学者は平の委員にすぎませんでした)。
委員長に選ばれたのは、当時、同研究所の言語教育研究部長で、JIS X 0208の83年改正をほとんど独力でおこなったといわれる、あの野村雅昭氏でした。野村氏が献身的な民主主義者であることは、すでに見たとおりです。
さて、JIS X 0212の漢字選定作業を実際におこなったのは、国立国文学資料館出身で、いわき明星大教授の田嶋一夫氏でした。
田嶋氏は中世文学専攻で、国立国文学資料館勤務時代に、国文学資料のデータベースづくりを10年間担当した人で、松尾氏によれば「必要な漢字であれば、多くなってもJIS化すべきである」という考えを持っていたそうです。JIS X 0208は、旁の邑(オオザト)と偏の阜(コザト)をいっしょにしてしまうなど、おもしろい部首分けをしていましたが、JIS X 0212では普通の漢和辞典の部首順でならんでいます。国立国語研究所系の漢字制限論とは別の思想でつくられているといっていいでしょう。
田嶋氏の6千字追加という案に、漢字制限こそ民主日本の生命線と考える野村委員長は反発し、1987年12月の委員長辞任につながったということです。
新しい委員長には田嶋氏が就任し、5801字を収録したJIS X 0212は1990年に制定のはこびとなるのですが、よそ者を排除する思想でつくられたシフトJISが普及していたために、画餅におわってしまったのはすでに述べたとおりです。
1990年の時点では、すでにシフトJISが事実上の標準の地位を確立していたわけですから、実装方法について現実的な方策(たとえば、次節で紹介するJIS X 0213のような)を考えるべきだったという批判が出てくるのは仕方がないでしょうが、このあたりが当時の限界だったと思います。
JIS X 0208の第3次規格は1990年ですから、第4次規格の制定は1995年におこなわれるはずでしたが、事務局側が当初、改正の必要を認めなかったために、準備がおくれました。
今回の改正では、過去の改正と異なり、文字種の追加や字形変更、字体いれかえはおこなわれていません。その代わり、19年間、ずっと放置されてきた曖昧な部分や矛盾する部分、根拠薄弱な部分を洗いだし、明確化して、規格の名に値するものにする努力がはらわれました。JIS X 0201の改正を同時におこなう点も重要です。JIS X 0201は、1976年改正以来、ずっと見直しがおこなわれなかったために、国際規格との間に齟齬を生じていたからです。
主な改正点をあげれば、次の通りです。
漢字の典拠調査は1978年の第1次規格制定時にさかのぼっておこなわれ、JIS幽霊文字のいくつかは、よりどころとした漢字表の転記ミスだったことが判明したそうです。JIS X 0208はずっと既存の漢字表の切り貼りによってつくられてきたので、文字が足りないといわれる一方、幽霊文字の混入はどうしても避けられなかったのです。第1次規格制定において、日下部表とよばれる昭和初年の漢字表が大きな役割をはたしたことを発掘した点も、今回の改正の成果でしょう。
「合成文字」云々というのは、1978年当時には、数字やアルファベットの上に、合成用の大きな○を重ねて印字すれば、「①」や「②」といった丸つき数字や丸つきアルファベットになると信じられていたことを指します。合成文字が可能という前提のもとに、JIS X 0208では合成用の「○」が符号化され、丸つき数字や丸つきアルファベットは、強い要望があったにもかかわらず、符号化されませんでした。
しかし、重ね打ちによる合成文字はぶかっこうで、印字品質をもとめる日本のユーザーが納得するはずはありませんし、第一、画面上に表示することすらできません。そのため、各メーカーはシステム外字として丸つき数字や丸つきアルファベットを独自に符号化しており、データ交換の際の障害となってきました。合成文字が実用にならないことを遅ればせながら認め、丸つき数字や丸つきアルファベットの符号化の必要性を確認した点は、前進だと思います。
83年「改正」の原因となった「字体」概念と「字形」概念の混乱を整理した上で、「包摂」を定義した点は、問題点がはっきりしたとはいえ、いささか疑問があります。第4次規格では「高」と「![]() 」、「吉」と「
」、「吉」と「![]() 」の違いは、単なる字形の違い(デザイン差)ではなく、字体の違い(異体字)であり、その上で複数の字体を一つのコードポイントに包摂するという手続きを踏んでいます。
」の違いは、単なる字形の違い(デザイン差)ではなく、字体の違い(異体字)であり、その上で複数の字体を一つのコードポイントに包摂するという手続きを踏んでいます。
この規格では、一つの区点位置が複数の字体を区別しないことを"包摂"とよび、包摂を字体ごと(区点位置ごとではない)に定めた"包摂規準"を規定として設けることによって、この明確化を図った。
すべての字形、あるいは文字デザインにコードポイントを割り当てていくのは不可能ですし、また新しいフォントの開発を阻害することにもなりますから、文字デザインのバリエーションを包摂するのは当然のことです。しかし、「高」と「![]() 」、「吉」と「
」、「吉」と「![]() 」のように、社会的に別の字体として認識されている異体字を、一つのコードポイントにまとめてしまい、どうしても特定の字体にこだわるのならフォント切り換えで対応せよというのは、あまりにも乱暴な話ではないでしょうか(この点については、「小は大をかねるか?」をご覧ください)。
」のように、社会的に別の字体として認識されている異体字を、一つのコードポイントにまとめてしまい、どうしても特定の字体にこだわるのならフォント切り換えで対応せよというのは、あまりにも乱暴な話ではないでしょうか(この点については、「小は大をかねるか?」をご覧ください)。
既存の「自由領域」を使用禁止にした点については、さまざまな議論があるでしょうが(前章でふれたように、97年改正のJCS委員会では、「自由領域」はそもそも存在していなかったと考えているようです)、本格的なネットワーク化社会の到来をむかえて、従来の外字を野放しにしておくわけにいかなくなったのも事実です。本当は1983年か1990年の時点で、各社の実装しているシステム外字を調査してJIS X 0208に追加し、外字禁止を打ちだしていれば混乱がすくなくてすんだのですが。
シフトJISのとりこみも大きな意義があります。私製文字コードだからといって放置した結果、ベンダーによって78JISと83JISの字形が混在するなど、さまざまな混乱が起こっていますから、JISによる標準化は遅かったとはいえ、必要な措置といえます。
ただし、ISO 2022系だったもともとのJIS X 0208 & JIS X 0212にくわえて、次章でのべるユニコード系の JIS X 0221、それに今回のシフトJISと、たがいに互換性のない三つの系統の文字コードが、JISの名で制定されてしまったことは確認しておかなくてはなりません。歴史的な経緯があるといっても、他の分野のJIS規格ではありえないような異常事態が出来しているのです。
JIS X 0208の第4次規格は、以上の改正点だけをとっても、きわめて重要で意義のある改正だということがおわかりかと思いますが、もう一つ、注目すべき点があります。それは、今回の改正が、1998年後半に公開レビューが予定されているJIS第3水準・第4水準文字拡張のための地ならしという面をもっていることです。
JIS X 0212補助漢字は、準備段階で「第3水準漢字」と呼ばれていましたが、ここでいう第3水準・第4水準の拡張は、JIS X 0212とはまったく別の新規格で、JIS X 0213という名称になるようです
JIS X 0213は、まだマスコミではあまり報道されておらず、公開資料も限られていますが、原案委員会の芝野耕司委員長に直接うかがったところ、以下のことがわかりました。
従来のJIS漢字コードでは、JIS X 0208にせよ、JIS X 0212にせよ、既成の漢字表を切り貼りしてつくられてきましたが、JIS X 0213は、はじめて地名資料50万件、人名資料6千万件、教科書千冊以上、その他、厖大な一次資料で文字同定・使用頻度調査をおこなうということです。5千字というのは、あくまでも現時点における一応の目標ということで、今後の調査結果いかんでは、増える可能性もなくはないようですが、下図をご覧になればおわかりのよに、シフトJISでは増やす余地はありません。シフトJISでも文字が増やせるという点がJIS X 0213の最大のメリットですから、これ以上の拡張は意味がないでしょう。
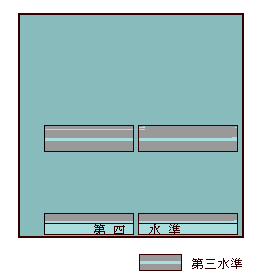
JIS X 0213は補助漢字とライバル関係にあるといってもいいかもしれません(現JCS委員会の中には補助漢字を廃止すべしという強い意見があるそうです)。補助漢字はシフトJISといっしょには使えませんが、JIS X 0213はシフトJISと共存できるというか、一体化するのは圧倒的な利点です。補助漢字はユニコードにすべてふくまれていますが、JIS X 0213はユニコードにはいっていない文字も符号化するようです。
1983年の時点で、例のイデオロギー本位の改悪ではなく、このような実のある拡張がおこなわれていたら、どんなにすばらしかったろうと思います。1990年の時点でも、既存外字の使用禁止で混乱はおこったでしょうが、十分意義があったにちがいありません。しかし、1998年という時点ではどうでしょうか。
JIS X 0213の最大のメリットであり、デメリットでもあるのは、JIS X 0208と完全に一体化し、継ぎ目のわからない単一の文字セットとなってしまう点です。JIS X 0213は、規格番号を見ると別の文字集合のように思うかもしれませんが、実質的には JIS X 0208の5000字拡張です。JIS X 0208は、83年、90年と数字づつ文字種を拡張してきましたが、JIS X 0213と一体化することで、総計1万1千字余の新拡張JISというべき文字セットにうまれかわるのです。だから、フォントを JIS X 0213対応のものにいれかえさえすれば、ハードウェアも、OSも、アプリケーションもそのままの状態で6000字余から1万1千字余に増え、ネットワークに流すこともできます。受けて側にもJIS X 0213対応フォントがはいっていなければ表示できませんが、ネットワークに接続したコンピュータには、いやおうなしに新拡張JIS(JIS X 0208+JIS X 0213)が流れこんでくるわけです。。
JIS X 0212(補助漢字)は、OSの根本的な改造が必要だったために普及せずに終わろうとしていますが、JIS X 0213はその心配はないでしょう(唯一の脅威はXKPが普及することでしょうか。JIS X 0213とXKPは共存できません)。だれか一人がJIS X 0213を使いはじめると、そのネットワークにつながっている全員が嫌でもJIS X 0213を使わざるをえなくなるという事態も想定されますから、ひじょうに早く普及するでしょう。
しかし、そうなると、既存の外字を使ったこれまでのデータがすべて破壊されることになります。外字は使っていないから大丈夫という人も安心は出来ません。自分で字形データをしこしこ作るユーザー外字は使っていないとしても、ベンダー側で用意したシステム外字は知らないうちに使っている可能性があるからです。JIS X 0213では、外字はすべて別の文字におきかわってしまうのです。83年改正時には、300字の字形変更であれだけのトラブルがおきましたが、JIS X 0213はまったく違う字に化けてしまうのですから、さらに深刻です。「(株)」や「(有)」なんていうシステム外字を多用している得意先リストなどはどうなるのでしょうね。
影響は JIS X 0213を使っている側にもおよびます。97年になって原則禁止となったシステム外字を使っているコンピュータは、ワープロ専用機も含めれば、まだ多数が現役ですから、そうしたマシンがネットワークにつながっていれば、JIS X 0213に対応したマシンでも文字が化けまくるのです。
困ったことに、新拡張JIS(JIS X 0208+JIS X 0213)を使っているのか、従来のJISコード(JIS X 0208)を使っているのかは、原理的にも実際的にも判別不可能です。JIS X 0213が JIS X 0208と完全に一体化することにはデメリットもあるというのは、そういう意味です。
これまではコンピュータは社会生活のごく小部分を覆うものにすぎず、ネットワークといってもたかがしれていました。文字コードにない文字は外字をつくればよかったのです。しかし、これから到来する本格的なネットワーク化社会ではそういうわけにはいきません。コンピュータは社会生活のほとんどすべての面を覆いつくし、コンピュータで情報交換できない文字は存在しないことになってしまうからです。
「現代日本語を符号化するために十分な文字集合を提供する」という目標は実用的だと思いますが、過去の日本語はどうなるのでしょうか? 国文学や歴史学はもちろん、法学や医学など学術研究の各分野では、過去の日本語も必要なのです。ネットワーク化社会が到来しようとしている現在、歴史的存在としての日本語を表記するための包括的な文字コードを、早急に規格化する必要があると思うのですが、どうでしょうか。
Copyright 1997 Kato Koiti
This page was created on Dec09 1996; Last updated on Oct27 1997.