加藤弘一
「文字コード問題早わかり」は1996年11月に「カタカナ篇」をかわきりに順次公開し、翌年3月の「ユニコード篇」で一応の完結を見ました。
その後、『電脳社会の日本語』の取材のために関係者に直接お話をうかがったり、関連資料の収集につとめたところ、多くの新事実を発掘するとともに、通説の誤りも見つかりました。本ページにも多くの誤りがありますが、直すとしたらゼロから書き直さなければならないので、内容の更新は1998年5月を最後におこなっていません。
本ページは引きつづき参考として公開をつづけますが、文字コードの歴史に興味のある方は拙著『電脳社会の日本語』(文春新書)をお読みください。(2000年 4月 7日)
1970年代にはいると、コンピュータの進歩によって、漢字を使えるようにしようという試みがあちこちではじまりました。『メディアの興亡』(文春文庫)は、日本経済新聞社がIBMと共同で、独自の漢字組版システムを開発する経緯を追ったルポルタージュの傑作ですが、この時代は新聞社だけでなく、生命保険会社など、大型コンピュータを導入した多くの会社が、業務内容に応じた独自の漢字コードの制定に着手していたのです。
企業の要請もあって、例によって泥縄的ですが、1978年に漢字をふくむ新たな文字コードが、JIS X 0208「情報交換用漢字符号系」として制定されました。この年は、日本語ワープロ第一号も誕生していて、コンピュータに普及の上で節目となる年でした。JIS X 201の項で述べたのと同じ理由で、JIS X 0208は1987年まではJIS C 6226と呼ばれていましたが、ここでは、引用以外は、JIS X 0208で通します。
漢字は諸橋大漢和で約5万字、大正期から進められていた漢字制限論の成果というべき1949年の当用漢字表でも1850字ですから、7bit(128文字種)や8bit(256文字種)でおさまるはずがありません。そこで7bitないし8bitの番号を、何丁目何番地のように、複数組みあわせて1文字をあらわすようにしたのです。
コンピュータの世界ではデータを処理する際の最小単位をバイトといいますが、このように二つ以上のバイトで1文字をあらわす文字コードを、複数バイト・コードとか、マルチ・バイト・コードと呼びます。8bitを1バイトとすることが多いですが、6bitや7bitの1バイトをつかう環境もあります。「ユニコード篇」でとりあげるUnicodeは、16bitないし32bitを処理の最小単位とするので、マルチ・バイト・コードではなく、シングル・バイト・コードです。
8bitの番号を二つくみあわせて、「34丁目の41番地」とか「3B丁目の7A番地」という具合にあらわすのですから、単純に考えれば、256 x 256 = 65536文字種となるはずですが、そうは問屋がおろしません。ネットワークの世界では、前章で紹介したASCIIやISO 646で符号化されたデータがすでにゆきわたっていますから、7bitの文字コードとの共存を考えなければならないのです(どのように共存させるかを決めたのが、次章で紹介するISO 2022という国際規格です)。
JIS X 0208は「情報交換用符号化漢字集合」とあるように、外部コード、つまり他のコンピュータとの情報交換に使うコードとして設計されました。内部コードなら65536文字種をフルに使えるところですが、7bitのASCIIコードしか受けつけないマシンが日本国内にも多かったので、2進数の8桁目を切り捨てられても大丈夫なように、7bitの範囲であらわせる番号(0-127)だけを使うという枠をはめることにしたのです。
ISO 2022によれば、7bitの範囲ですら、すべての番号を使えるわけではありません。JIS X 0201の左半分(前半)をもう一度示すと、
| 範囲 | 文字 | 使用 |
|---|---|---|
| 00~1F | 制御文字 | 不可 |
| 20~40 | 記号・数字 | 可能 |
| 41~7A | アルファベット | |
| 7B~7F | 記号 | |
| 80~A0 | 空き領域 | 不可 |
| A1~A5 | 句読点 | |
| A6~DD | カタカナ | |
| E0~FF | 空き領域 |
のように、00h~1Fhの32個分の番号は制御文字にわりあてられています。制御文字は画面には表示されないけれども、「テキスト開始」とか、「伝送終了」、「BackSpace」などマシンの動作そのものにかかわる符号ですから、絶対に手をつけるわけにはいきません。というわけで、7bit(128)から32個を引いた96個の番号しか使えないことになります。実際は、さらに前後一つづつ余裕をみて("Space"と"Delete"にあてることになっています)、21hから7Ehまでの94個の範囲しか使いません。
このように前後から制限された8bitの番号を、「34丁目の41番地」とか「3B丁目の7A番地」という具合に二つくみあわせると、94 x 94 = 8836個の番号が使える計算です。JIS X 0208の収録文字種の上限は8836個ということになります。なお、最初の15行(15区)分は数字やアルファベット、仮名、キリル文字にあてられ、漢字は16行目(16区)からはじまります。
この設計は後につくられる補助漢字(JIS X 0212)や中国のGB2312でも踏襲されました。韓国のKSC5601は96 x 96ですが、やはり15行(区)までを非漢字にあて、16行(区)目からハングルがはじまります(日本の第1水準漢字の部分がハングル、第2水準漢字の部分が韓国漢字)。
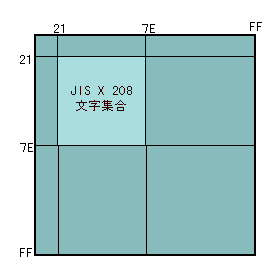
さて、21hから7Ehまでの94個の番号を二つ組み合わせるわけですが、一列に並べるより、縦軸と横軸にそれぞれ番号をふり、2次元の表の形にした方が、文字が探しやすくなるでしょう。JISでは、縦軸に最初の番号(第1バイト)、横軸に後ろの番号(第2バイト)をふります。これを2バイト平面といいます。2バイト平面におけるJIS X 0208文字集合を示してみます。
「字」という文字がJIS X 0208でわりあてられた番号(いわゆるJISコード)は「3B7A」ですが、これは縦軸の"3B"と横軸の"7A"の交点としてあらわせます。
現在は仮名漢字変換プログラム(以前はFEP、最近は日本語IMEとか日本語インプットメソッドと呼ばれています)が進歩したので、文字コードを意識することはほとんどありませんが、1980年代の初期までは、コード入力といって、ワープロ漢字辞典で一字づつ文字につけられた番号を調べ、キーボードからその番号を入力するという、恐ろしくめんどくさいことをやっていました。
仮名漢字変換プログラムが登場しても、最初の頃は単漢字変換などという、今からふりかえると信じられないくらい幼稚なものでしたから、なかなか目当ての漢字が出てこず、コード入力をした方が早いということがしばしばあったのです。しかも、16進数は数字とアルファベットの両方を使っているので入力が大変です。もし数字だけですむなら、片手で入力できるテンキーが使えて楽になるでしょう。
別に入力の手間を軽減するためというわけではありませんが、文字の位置を10進数であらわした区点コードも規格化されました。区点コードは"21h"から"7Eh"までの94個の16進数に"01"から"94"までの94個の10進数をふったもので、好都合なことに2桁におさまっています。
第1バイトが"21h"の横列にならんだ文字を01区の文字集合と呼び、順に01番、02番、03番、と番号をふっていき、最後の"217E"の文字(「◇」です)が94番となり、01区の01点とか、01区の02点、01区の94点という呼び方をします。"22h"の横列が02区、"23h"の横列が03区になるのはいうまでもありません。ちなみに、「字」という文字("3B"の横列の"7A"番目)は27区の90点で、区点コードは2790となります。
ワープロ漢字辞典の類にはJISコードとともに区点コードがのっているので、おなじみですね。読みのわからない漢字は、今でもコード入力することがありますが、区点コードを使う人が多いようです。
次に区点コードとJISコードを併記した漢字表を示しましょう。
| 01 | 02 | 03 | 04 | 05 | 06 | 90 | 91 | 92 | 93 | 94 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 21 | 22 | 23 | 24 | 25 | 26 | 7A | 7B | 7C | 7D | 7E | ||||||||
| 01 | 21 | sp | 、 | 。 | , | . | ・ | 中略 | ★ | ○ | ● | ◎ | ◇ | |||||
| 02 | 22 | ◆ | □ | △ | ▲ | 保留 | 保留領域 | |||||||||||
| 03 | 23 | 保留領域 | z | 保留領域 | ||||||||||||||
| 04 | 24 | ぁ | あ | ぃ | い | ぇ | え | 保留領域 | ||||||||||
| 05 | 25 | ァ | ア | ィ | イ | ゥ | ウ | 保留領域 | ||||||||||
| 06 | 26 | Α | Β | Γ | Δ | Ε | Ζ | 保留領域 | ||||||||||
| 07 | 27 | А | Б | В | Г | Д | Е | 保留領域 | ||||||||||
| 08 | 28 | ─ | │ | ┌ | ┐ | ┘ | └ | 自由領域 | ||||||||||
| . | . | |||||||||||||||||
| . | . | |||||||||||||||||
| 15 | 2F | |||||||||||||||||
| 16 | 30 | 亜 | 唖 | 娃 | 阿 | 哀 | 愛 | 引 | 飲 | 淫 | 胤 | 蔭 | ||||||
| 17 | 31 | 院 | 陰 | 隠 | 韻 | 吋 | 右 | 凹 | 央 | 奥 | 往 | 応 | ||||||
02区や04区の後ろに保留領域という、文字のわりあてられていない空き番号が存在します(上の図は一部はしょった図なので、わかりにくいかもしれませんが)。ここは将来の拡張のための場所で、勝手に使ってはいけないとされています(改正ごとに増える文字は保留領域にわりあてられていきました)。
それに対して、非漢字と漢字の境界にあたる09区から15区の空白域は自由領域とされてきました(1997年3月から、この名称はなくなります)。JIS X 0208:1983の解説には「この領域は、情報交換当事者の協定によって、一時的・局所的に文字を割り当てて利用しても構わない」とあります。この規格表にない文字や記号は、自分たちで勝手に作り、自由領域の中にわりあててよろしいということですね。これが正式の住所(コードポイント)をもたない規格外の文字、いわゆる外字を使用する根拠になっています。漢字の終わる84区以降(85区から94区)も自由領域とされてきました。
もっとも、この点には異論が出されています。JIS X 0208:1997を審議する第4次JIS原案委員会の芝野耕司主査によれば、JIS X 0208はISOに登録されているが、ISOに登録された文字コード表では空き領域はすべて保留領域としてあつかうのが原則だから、自由領域が存在する余地はない。規格表の解説で自由領域とされているものは、ISO登録が完了した瞬間に消滅しているはずだから、外字の使用は一切まかりならんというのです(実際、1997年3月から施行される新しいJIS X 0208:1997では、自由領域が廃止されるのですが、この点については「続・漢字篇」でふれます)。
理屈としてはその通りでしょうが、論理上あってはならない「自由領域」に、外字という住所不定の文字、いわばホームレス文字の一時滞在を認めてきたおかげで、JIS X 0208の欠点が補われてきたのも事実だと思います。
外字にはメーカー側があらかじめ用意したシステム外字(メーカー定義文字とも言います)と、ユーザーが自分で字形データ(グリフと言います。グリフの集まったものがフォントです)を作成し、組みこむユーザー外字(ユーザー定義文字)の二種類があります。システム外字は機種によって変わってくるので、機種依存文字と呼ばれることがあります。その伝でいえば、ユーザー外字はユーザー依存文字ですね。なお、かつて圧倒的なシェアを誇った9801シリーズのシステム外字は、良くも悪くも影響力が大きかったので、俗に98文字と呼ばれていました。
外字領域のうち、どこをシステム外字領域として、どこをユーザー外字領域とするかは、メーカーしだいです。もちろん、どんな文字や記号をシステム外字にするかも、メーカー独自の判断によりますから、メーカー依存文字ということになります。いや、パソコンやワープロ専用機を出している大手メーカーは、事業部制をとっていますから、事業部依存文字といった方がいいかもしれません。同じメーカーなのに、パソコンとワープロ専用機ではシステム外字が違うなんていうことがあるのです。中には同じ事業部から出ている同一ブランドの製品なのに、製造時期によって、付属の注文書の「5インチフロッピー」(5インチフロッピー)が「5ヤードフロッピー」に化けてしまうというおちゃめなワープロ専用機まであったそうです(この注文書で注文すると、本当に直径4m60cmの巨大フロッピーがとどくのでしょうか)。
先ほど、外字は正式な住所(コードポイント)をもたないホームレス文字だということを書きましたが、残念ながら、一部のメーカーでは、ホームレス文字としかいいようのないぞんざいなあつかいをしているのも事実です。
ユーザー外字はもちろんのこと、システム外字を使った文書は機種が違うと読めなかったり、違う文字に化けたりします。外字はホームレス文字なのですから、当然といえば当然ですが、「情報交換用符号」という趣旨からすれば、芝野主査の指摘を待つまでもなく、鬼子的な存在であり、確かに一日も早く強制退去させるべきなのかもしれません。
最近、『新潮文庫の100冊』のようなCD-ROM本が出ていますが、JISに無い漢字を表示するのにかなり苦労しているようです。単純に考えれば、JISに無い漢字はユーザー外字に組みこめばいいように思うかもしれませんが、利用者の環境を壊すおそれがあるので、その手は使えません。では、システム外字はどうかというと、WindowsとMacintoshの両方で使えるハイブリッド・ディスクにするには、WindowsとMacintoshでシステム外字の位置がちがうので、やはり駄目です。『新潮文庫の100冊』の製作にあたったボイジャーという会社では、JISにある非漢字文字のうち、文学作品では絶対に出てこない「▲」や「∞」のような記号を、JISに無い漢字に置き換えた専用フォントをつくり、その専用フォントをCD-ROMに同梱するという苦肉の策をとっています。
システム外字には「㍻」、「トン」、「①」のように(順に「平成」、「トン」、「丸つきの1」ですが、ちゃんと見えますか?)、多くの人が必要とするのにJISには含まれていない文字や記号が選ばれていますが、ワープロ専用機ではトランプのマークがあったり、星占いの記号があったりと、ひじょうにバラエティに富んでいました。パソコンはMS-DOSという標準の基本ソフトがあったのですが、NEC版MS-DOSか、富士通版MS-DOSか、三菱版MS-DOSかで、システム外字の内容はばらばらでした(Windows時代になっても、NEC拡張とIBM拡張があり、マイクロソフト・ブランドのWindowsではこの二種類の拡張文字が重複してはいっています)。しかし、なんといっても異色の存在は、NECが作りだした2バイト半角文字でしょう。
本題とはずれますが、ここで全角・半角という言葉を説明しておきましょう。
全角・半角という言葉は、もともと印刷用語だったようですが、JIS X 0201で符号化されたアルファベット、数字、カタカナ(ANK文字)が半角だったことから、JIS X 0208で重複して符号化されたアルファベット、数字、カタカナは漢字と同じ全角にして区別するという暗黙の了解が生れたようです。
「暗黙」というのは、文字コード関連の規格票には全角・半角の規定がないからです。全角・半角を規定しているのは、1986年に制定されたJIS B 0191「日本語ワードプロセッサ用語」という規格です。ここには全角は縦横がほぼ同じとあって、半角は「読み方向の幅が半分」とあります。なぜ横幅ではなく「読み方向」なのか、縦書き半角は上下につぶれた形になるのか、なぜワープロ関連規格が一般機械のジャンルである「B」に分類されているのか、なぜ情報処理のジャンルである「X」に移さなかったのか、謎だらけですが、所詮、JISは黄色い猿のための規格ですから、この程度の不一致をとやかく言ってもはじまりません。
日本語の印刷は縦組が基本ですから、同一のポイント数の活字の横幅は全角と半角、1/4角しかありませんが、欧文の場合、大文字と小文字で文字幅が違ってきますし、「i」より「w」の方が幅が広いというように、大文字どうし、小文字どうしでも横幅が異なります。アルファベットの特性からいって、横幅を変えた方が判読しやすいし、見た目も自然なのです。ただしタイプライターは別で、機械的制約から「i」も「I」も「w」も「W」もすべて同じ横幅です。文字によって横幅を変えると、紙送りのピッチも変えなければなりませんから、仕方がないのです。欧文印刷の世界では、横幅が文字によってことなる活字をプロポーショナルフォント、タイプライターのように横幅が一定の活字を等幅フォントと呼びます。
WindowsなどのGUI環境では、等幅フォントを選択することも可能ですが、プロポーショナルフォントが一般的です。しかし、コンピュータの表示はごく最近まで等幅フォントが普通でした。
初期のコンピュータは出力装置にテレタイプを流用していました。テレタイプとはテレ+タイプで、遠くにあるタイプライターという意味です。こちらでタイプライターのような端末から文字を打ちこむと、信号が遠隔地に伝えられ、向こうで文字が印字されるわけです。コンピュータの計算結果を打ちだすにはうってつけの機械でしたが、プロポーショナルフォントにすると、文字によって紙送りのピッチを変えなければなりません。当時の技術水準ではそういう処理にまでは手がまわりませんでしたし、計算結果がわかればよかったので、タイプライターと同じように等幅フォントですませたのです。MS-DOSはあとから出てきたとはいえ、技術レベルの低い幼稚なシステムでしたから、表示も印字も等幅フォントを使っていました(WordPerfectのような高度な英文ワープロは、独自の表示系を組みこむことで、プロポーショナルフォントを使っていましたが)。
JIS X 0201の規格票ではANK文字は全角文字で例示されていますが、コンピュータではアメリカ生まれなので、アルファベットも数字も横縦比率がほぼ1対2の縦長の等幅フォントで実装されていました。アルファベットの場合、もともと縦長のデザインですし、大文字と小文字を区別するには横と縦の比率が1:2だと切りよくおさまったのです。コンピュータでは、画面に表示するにも、紙に印字するにも、点(ドットと言います)の集まりで文字を表現しますが、横8ドット、縦16ドットの文字は効率がよく、見ばえもするので標準になりました。規格票では全角だったカタカナも、実装される際には、アルファベットに合わせて、縦長の字形になりました。当時の技術水準では、カタカナだけ別あつかいするわけにはいかなかったのです。この字形が後に言う半角カナです。
カタカナは 8 x 16ドットで十分表現できますが、漢字は画数が多くなると無理です。そこで、JIS X 0208で漢字が符号化されると、印刷活字そのままのほぼ正方形の字形が実装されました。先にふれたように、JIS X 0208には、JIS X 0201ですでに符号化されていたANK文字(アルファベット・数字・カタカナ)も重複してはいっていましたが、JIS X 0208の方のアルファベット・数字・カタカナは漢字に合わせて、全角で実装されました。これがいわゆる全角文字です。
2バイト文字が全角、1バイト文字が半角だと、文字列のデータ量(バイト数)と表示幅(表示桁数)が一致します。特にシフトJISですと、文字集合を呼びだす隠し文字(エスケープシークェンス)がはさまりませんので、文字列のバイト数=表示桁数になり、アメリカ製のソフトを移植する上では工程がいくつかはぶけました。シフトJISが支持された最大の理由はこれでした。真似ばかりしている黄色い猿にしては上出来ですが、ケガの功名といったところでしょうか。
閑話休題。同じ文字を二重にコード化しているのは混乱のもとですが、それに輪をかけるように、NECは2バイトなのに半角の幅しかないANK文字ひとそろいをシステム外字として作ってしまいました(09区と10区にわりあてていました)。同じ2バイトでも、表示する文字幅がちがってくるので、例外的な処理をしなければならず、なんのためにシフトJISを使うのだかわからないという奇妙な事態が生まれたのです。9801シリーズのソフトをつくるプログラマーたちは余計な苦労をさせられると嘆いたということですが、NECのマシンでは全角文字=2バイト文字ではあっても、半角文字=1バイト文字でない点は注意しておいた方がいいでしょう。
コンピュータを単独で使っている分には外字の問題は表面化しません。空き番号を保留領域と自由領域にわけ、外字使用を推奨してきたJISの方針は、論理的にはともかく、現実的な観点からいえば、1978年の時点ではまったく正しく、1983年時点でも妥当といえたでしょう。多分、1990年段階でも間違っていなかったと思います(6年前に、インターネットが現在のように広まるなどと、誰に予測できたでしょうか!)。しかし、ネットワークが当たり前になり、マシン内部のハードディスクにおいた文書と、インターネット上の文書がまったく同じようにあつかえる環境が現実となりつつある今日、正式のコードポイントをもたない外字の存在はいよいよ微妙なものになっています。
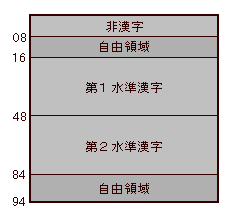
1978年のJIS X 0208(正確には JIS C 6226-1978)では、最初に非漢字453字がおかれ、自由領域をはさんでから、16区から84区までの範囲に、漢字6349字がわりあてられていました(現在は漢字が6字、非漢字が104字増えています)。6349字は一まとめに配列されているわけではなく、第一水準漢字2965字と第二水準漢字3384字にわけられ、それぞれ16区から47区、48区から83区に配列されています(第一水準の最後の47区51点以降、94点までは保留領域としてあけてあり、第二水準は48区01点からはじまります)。
さて、この6349字がどのようにして集められたかですが、JIS X 0208:1997改正のための第4次JIS原案委員会のつくった「JIS X 0208 改正案説明資料」によれば、行政管理庁(現・総務庁)行政管理局が1974年に作成した「行政情報処理用標準漢字選定のための漢字使用頻度および対応分析結果」という資料をもとにしたということです。
信州大の池田証寿さんが報告されていますが、この資料は「国土行政区画総覧」、「日本生命人名漢字表」、「行政情報処理用基本漢字」、「情報処理学会漢字コード標準化委員会標準コード用漢字表試案」という四つの漢字表を転記し、混ぜたものですが、このうち「国土行政区画総覧」は地名、「日本生命人名漢字表」は人名、「行政情報処理用基本漢字」は公文書に使われる漢字を採録した表で、JIS X 0208の原型と言えるでしょう。
地名、人名、公文書というのが、当時、コンピュータによる漢字処理の主な用途として考えられていたわけですから、当然といえば当然ですが、問題は最後の「情報処理学会漢字表試案」です。
| 漢字表 | 分類 | 漢字数 |
|---|---|---|
| 国土行政区画総覧使用漢字 | 地名 | 3251 |
| 日本生命収容人名表 | 人名 | 3044 |
| 行政情報処理基本漢字 | 公文書 | 2817 |
| 情報処理学会漢字表試案 | 生活語彙 | 6086 |
第4次JCS案委員会の芝野委員長のご教示によれば、これは第1次JIS原案委員会に、国語学者としてただ一人くわわった国立国語研究所所長(当時)の林大氏が、昭和8年(1933年)出版の「現代国語思潮」の付録の日下部表という漢字表をもとにしてつくったものだということです(日下部表の存在はJIS X 208には一言もふれられていません)。なぜ1933年に作成された漢字表が、45年もたった1978年の時点で使われたかというと、さまざまな漢字表を収集したところ、この表だけが6000字をこえる漢字を収録していたからだそうです。
漢字について決めるのに、30人以上いる委員のうち、国語学畑の学者が一人しか参加していなかったというのは意外な感じがしますが、松尾博志氏の「漢字の行政を追う」(「しにか」1990年10月号)によると、当初、複数の国語学者が参加していたものの、たった一つの漢字をめぐって延々と論争をつづけるのでまったく作業が進まず、国語学者は全員が解任され、かわりに、文部官僚として戦後の漢字制限的な国語政策にかかわった林氏をあらたにむかえ、漢字選定の実務を林氏たった一人に委任したとあります。
しかし、97年改正のための委員会があらたに調査したところによると、この記述は情報処理学会が1970年につくった漢字コード委員会と1978年のJIS原案委員会を混同したものではないかということです。1970年の呉越同舟委員会の紛糾にこりたのか、漢字コード委員会は1973年から国語学者を国立国語研究所系にしぼって再出発し、4年間にわたる作業の結果、1976年に上述の「情報処理学会漢字表試案」をまとめました。1978年のJIS原案委員会は、はじめから国語学者としては、林氏ただ一人を委員に選び、「情報処理学会漢字表試案」をもとに文字コードの制定にとりかかったのです。
昭和初年と現代では、戦争と高度経済成長をはさんで社会の様相が一変しています。特に第2次大戦の敗戦の影響は甚大でした。
敗戦の虚脱感で日本人は自信をうしない、それまでの神がかりの鬼畜米英から、一転して極端な欧米崇拝に走りました。GHQ司令部に日本をアメリカの四九番目の州にしてくれという投書が流行したとか、マッカーサー元帥の子どもがほしいという女性のラブレターがGHQに殺到したとか、「小説の神様」とまでいわれた文学者が日本語を廃止してフランス語を国語にしろと言いだしたとか、今から見ると笑い話としかおもえないことがいろいろあったのですが、こうした混乱に乗じて、明るい民主日本を建設するには、封建的な漢字文化を撲滅しなくてはならないと信じる人々が勢力を拡大し、1946年11月に悪名高い当用漢字表1800字を制定しました。
当用漢字表は、「まえがき」に「法令・公用文書・新聞・雑誌および一般社会で、使用する漢字の範囲を示したもの」とあるように、漢字の使用を厳しく制限するものでした。内閣告示および内閣訓令によって公布されたものですから、官公庁では当用漢字表にない漢字を使うのはご法度でしたし、教育現場でもうるさく遵守がもとめられました。新聞でも、「誘拐」を「誘かい」、「恐喝」を「恐かつ」、「泥棒」を「どろ棒」と表記するという具合に、自主規制がおこなわれました。
しかも、当用漢字表の「使用上の注意事項」には「この表の漢字で書きあらわせないことばは、なるべくかな書きする」、「専門用語については、この表を基準として、整理することが望ましい」とあり、漢字を使わなくてすむよう、日本語そのものを改造しようという意図がはっきりうちだされています。漢字撲滅を叫ぶ人々にとっては、1946年の当用漢字表は明るい民主日本建設の第一歩にすぎず、ゆくゆくは1800字を1500字に、さらには1000字に減らし、最終的には漢字を日本から一掃しようとしていました(信じられないでしょうが、本当にそう考えていたのです)。
このいわゆる「国語民主化」政策は、各方面に甚大なる影響をおよぼし、良い悪いはともかく、漢字のみならず、日本語全般に大きな変化を引きおこしました。
JIS X 0208の収録漢字については、「璽」のような今ではめったに使わない漢字がはいっている反面、尾てい骨の「てい」など医学に必要な文字に欠字が多いなど、数々の批判が出ていますが、昭和初年の漢字表がもとなのですから、現代生活に必要な漢字とずれていて当たり前なのです。
この6349字はどのようにして第1水準・第2水準にわけられたのでしょうか? そもそも、なぜわける必要があったのでしょうか?
1983年の JIS X 0208(正確には JIS C 6226-1983)の解説には「諸応用に共通のものとその他のものに2分する」とあります。わかりにくい文章ですが、ひらたくいえば、社会生活で使われることの多い漢字を第1水準に、使われることのすくない漢字を第2水準におくということでしょう。
1980年代前半までは半導体の製造技術が未熟で、7000字近い文字のフォントを一つのメモリーチップにおさめるなどという芸当は不可能でしたし、メモリーチップ自体もきわめて高価でした。そこで、どうせ多数のチップにわけなければならないのなら、使う頻度の高い第1水準漢字だけをおさめたチップ(漢字ROMと言いました)と、あまり使わない第2水準漢字だけのチップにわけ、第2水準漢字の方を別売にすることで、パソコンやワープロの本体価格を安くしようとしたのです(1983年に発売された最初の9801では、第1水準漢字ROMボードすら別売で、4万円という値段がついていました)。
わけ方の基準として、JIS X 0208解説は次の4つをあげます。
これでは漠然としすぎていて、よくわかりませんが、解説は「具体的な作業は, さまざまの漢字表を収集することから始められた」とつづけます。次は重要なので、引用してみます。
漢字表は最終的には37個収集された。それぞれの漢字の字数は、700~6800であった。特定の漢字が幾つの漢字表に採用されているかの数を、“重み”と名付ける。重みは、1~36であった。
また、37の漢字表を集計しても、重みの最大値が36にしかならないのは、「当用漢字外」と「当用漢字表」という、たがいに一致する文字が一字もない漢字表がはいっているからです。
どんな漢字表が集められたかを見ると、まずIBM、富士通、電総研漢字テレタイプ、写研、和文タイプライター文字配列表などのメーカーの漢字表、大蔵省主計局、大蔵省印刷局常用文字、内閣調査室収容漢字表などの政府機関の漢字表、読売新聞社基本活字、産経新聞社鑽孔機鍵盤文字配列、日本テレビ文字表示装置用字母、日本経済新聞社KBB文字表などの報道機関の漢字表、明治生命、日本生命など人名を多くあつかう企業の漢字表、そして語彙調査や『現代新聞の漢字調査』、当用漢字表などの国語学者の漢字表などがあります。
規格表付属の解説には、作られた目的も経緯ももとになった母集団もまったく異なる漢字表に、平等に一票づつあたえて、単純合計し、28以上の漢字表に共通して収録された漢字を第1水準の基本にしたというようなことが書かれていますが、第4次JIS原案委員会が第1次規格制定の過程を洗いなおした結果、最初にあげた四つの漢字表のうち、「国土行政区画総覧」と「日本生命人名漢字表」の二つには、一票以上の「重み」があたえられていたことが判明したそうです。
1978年頃のコンピュータの使われ方を考えると、これは現実的な選択だったと思います。当時はタイプ印刷のように、文字盤から漢字を一字づつひろって入力していたということですが、そんな入力法では帳簿や名簿に会社名や人名、所在地をいれるのがせいぜいで、素人がコンピュータで日記を書いて公開する時代が、わずか 20年後に来るなど、夢にも思わなかったでしょう。JIS X 0208の漢字の選択や水準のわけ方は、今となっては悪い冗談としか思えませんが、今日の感覚で、1978年のJISの判断を笑いものにしてはならないと思います。
それにしても、「姶」、「菰」、「菟」、「轡」、「鐙」、「鉦」、「塘」といった、お宝ものの文字が第1水準にはいっているのを見ると、昭和初年につくられた日下部表の影響を強く感じます。
その一方、「苺」、「丼」、「酩酊」、味「醂」などは第2水準ですし、「菫」が第1水準なのに「薔薇」が第2水準というのもおもしろいですね。「垉」、「墸」、「彁」、「恷」、「挧」、「暃」、「橸」、「汢」、「碵」、「穃」、「粫」、「蟐」、「袮」、「閠」、「鵈」のような、国文学者や漢学者が頭をかかえる正体不明文字があるというのもご愛敬です。
「椦」と「妛」の二つの文字については、第4次JIS原案委員会の手弁当による献身的な調査により、漢字表を作る際の転記ミスであることが判明したということですが、制定後19年もたった3回目の改正で、はじめて幽霊文字の調査をおこなったというのも、不思議な感じがします。
解説には「重み」とか「多変量解析」という言葉が出てきて、ぼくのような科学音痴はそれだけでハハアーとおそれいってしまいますが、よくよく考えてみると、本当に科学的といえるかどうか疑問です。馬の体重と鹿の体長と豚の体温というまったく比較にならないものを合計して平均をとるようなもので、こけおどしと言っては言いすぎでしょうか。従来のJIS X 0208にはこの種の矛盾がすくなくありません。以前、あるJIS関係者が、「文字コードが出鱈目なために、JIS規格全体が白い目で見られて迷惑している」という意味のことをパソコン通信のボードに書いていましたが、まったくその通りでしょう。
せっかく、国立国語研究所という機関がありながら、現代の漢字使用の実態については、新聞の用字調査しかしておらず、文字コード制定にあたって役に立つデータが提供できなかったというのも、困ったものです。当時の新聞は、当用漢字表に合わせて「誘かい」のように、表記を自主規制していましたから、わざわざ用字調査をしてもしようがないと思うのですが、やらないよりましといったところでしょうか。
JIS X 0208の制定は、1978年に突然もちあがったものではなく、1970年の情報処理学会の漢字コード委員会以来の活動の積み重ねの上におこなわれたものなのですから、漢字表を集計するといった泥縄の推計ではなく、本格的な用字調査をおこなう時間的余裕は十分あったはずです。百歩譲って、1978年には間に合わなかったとしても、1983年の最初の改正や、1990年の補助漢字(次章で述べます)制定には間にあったでしょう。こういう対応を見ていると、国立国語研究所は漢字制限論者の牙城という風評はあたっているのかなと思えてきます。
第1水準・第2水準の問題は、パソコン通信などでずいぶん論議されたようですが(第2水準漢字ROMはかつては3万円以上し、印刷するにはプリンタの方にも入れなければなりませんでした)、現在では半導体は安く高性能になりましたし、WindowsやMacintoshでは、半導体よりさらに安価なハードディスクにフォントを格納しておくようになりましたから、ある文字が第1水準か第2水準かなどということは問題にもなりません。それどころか、ちょっとしたソフトを買うと、さまざまな書体のフォントが 10種類くらいおまけでついてきます。ただ、JIS X 0208の漢字がどんな風に決められたかを知っておくことは、今後の文字コード問題を考える上で、貴重な示唆をあたえてくれると思います。
Copyright 1997 Kato Koiti
This page was created on Nov01 1996; Last updated on Aug27 1997.