この数年、安価なCD-ROM辞書や百科事典が次々と発売されている。筆者も何種類か使っているが、実に便利だ。百科事典などは、定期的にニュースや追加事項を提供してくれるところが多く、これも重宝している。
先日、ある百科事典の最新情報をダウンロードしたところ、江藤淳氏の訃報を「菅秀実」という文芸批評家が書いていた。見慣れない名前なので、しばらく考えこんだが、![]() 秀実氏かもしれないと思った(「
秀実氏かもしれないと思った(「![]() 」はスガと読むが、JISにはない)。御本人に確かめたわけではないので、断言はできないが。
」はスガと読むが、JISにはない)。御本人に確かめたわけではないので、断言はできないが。
JISにない漢字でも、外字として登録すれば、そのマシンでは表示できるし、プリントアウトもできる。しかし、メールでは送れない。ちょっと前までなら、ワープロやパソコンは清書マシンにすぎず、紙にそれらしく打ちだせれば十分だったが、ネットワーク社会ではそうはいかない。印刷という視点ではとらえきれない広範な変化が起きているのである。ここに文字コード問題の重大性がある。
2000年を目前にして、文字コードをめぐる動きがあわただしくなった。まず、漢字・記号類、約4千4百字を追加する新しいJIS規格(JIS X 0213という名称になる)の最終案が7月に発表され、開発にあたった日本規格協会JCS調査研究委員会(芝野耕司委員長)は2000年はじめの規格書の出版を予告した。国の正式の機関である日本工業標準調査会(JISC)の審議をへて、通産大臣の公示でJISとなる予定である。現行のJIS X 0208(以下、「JIS基本漢字」と呼ぶ)とあわせると、JIS漢字は1万40字に増えることになるが、後に述べるように、追加方法が裏技的であるために構造的文字化けがおこるなど、問題がすくなくない。
JISとは別に、数万字規模の巨大漢字セットを構築しようという四つのプロジェクトが進んでいる。「今昔文字鏡」、「e漢字」、「GTコード」、「拡張CJK」である。
そのうち「今昔文字鏡」と「e漢字」は昨年から成果を公開しており、外国の東洋学者をふくむさまざまな分野の研究者や、実務で漢字を必要とする人の間に急速に広まっている。TRONの関連で開発されている「GTコード」と、ISOのIRG(以下、「絵文字連絡会」と呼ぶ)が開発する拡張CJK(CJK統合漢字の拡張版)は、来年、公開の見こみである。
JISとユニコードを手厳しく批判してきた坂村健氏の提唱するTRONプロジェクト関連では、上記の四大文字セットのうち、「今昔文字鏡」を中心に、中国、台湾の漢字をあわせ、11万字の漢字を搭載した「超漢字」というBTRON準拠OSが11月に発売される。TRONプロジェクトは、全世界のありとあらゆる文字をコンピュータに使えるようにすることを公約に掲げ、三年ほど前から、季節の変り目がくると、「半年後に出る」という非公式のアナウンスを繰りかえしてきたが、いよいよ発売にこぎつけたわけである。
一方、ISOの国際文字コード制定活動の日本側窓口である情報処理学会情報規格調査会は、「文字コード標準体系検討専門委員会」(石崎俊委員長)を設置し、今後の日本の対応を審議していたが、その第一ステージの報告が9月に発表された。JISや「文字鏡」、「「e漢字」」、TRONのようにモノが出てくるわけではないので、地味だし、あまり報道されていないが、将来におよぼす影響は大きい。
本稿では、以上四つの話題をとりあげるが、前置きとして、文字コードの基本を簡単にふりかえっておきたい。なお、文字コードの議論では16進数を使うのが普通だが、なじみにくいので、あえて10進数で表記したことをお断りしておく。
コンピュータは数字しかあつかえないので、文字をあつかう場合も番号に直して処理する。文字を番号(符号)に直すことを「符号化する」という。
「文字」という語句は、コンピュータにとっては「149 182 142 154」という番号の集まりである。「文字」という語句を検索するとは「149 182 142 154」という番号のパターンを見つけることで、コンピュータが最も得意とするところだ。コンピュータは「電脳」などと気どっても、所詮は電子計算機なのである。
文字コードとは文字を番号に直すための対応表であり、一種の暗号表といえる。メールで文章を送る場合、実際は番号の羅列を送っているのだが、受け手側の対応表が送り手側の対応表と異なっていると、番号を元の文字にもどすことができず、意味不明の文字の羅列になる。中国や台湾のホームページを見ると、暗号のようなわけのわからない文字がならんでいるが、これは中国や台湾で使っている文字コード(コード表)が、日本のコンピュータの文字コードと異なるために起こる。
文字を数字に直すといっても、頭から通し番号をつけていけばいいわけではなく、コンピュータにわかるようにつける必要がある。文字コードの議論では、32とか94、128、256といった半端な数が出てくるが、これはコンピュータが2進法で動いているからである。また、処理するデータと、どう処理するかという指示は、どちらも数字の形でコンピュータにあたえられるので、文字に使える番号と使えない番号が出てくる。どのように番号をふるかを符号化形式といい、文字コードの構造で決まってくる。コンピュータ用の番号をふる前の文字の集まりを、文字セットという。文字コードと文字セットの関係は器と中味にあたる。
ユニコードの話題でかすみがちだが、世界各国の文字コードの基本になっているのはISO 2022という規格である。ISO 2022は世界各国の文字コードを共存させるための枠組で、インターネットもISO 2022をベースに構築されているし、UNIX系OSで使われているEUCという文字コードはISO 2022の簡易版である。
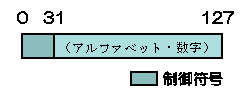
1962年に、アメリカのJISにあたるANSIという団体がASCII(アスキーと読む)という情報交換用文字コードを制定した。ASCIIは7bit(0から127までの128の数字)で文字をあらわすが、最初の32番までは制御符号(「改行」や「処理中止」、「送信終了」)に使い、残りの96文字のうち、32と127を除いた33〜126までの94の番号に「a」、「b」、「1」、「2」、「!」などの文字を配置する。ASCIIは他のマシンとの情報交換に用いるコードだが、設計がすぐれていたので、英語圏では内部処理にも使われるようになった。
ASCIIを元にISO 646というISOの規格が作られたが、英語はアルファベット26文字だけで間にあうものの、フランス語ではÇやâ、ドイツ語ではëや'öのような修飾つきアルファベット(本稿では「拡張アルファベット」と呼ぶ)が必要になる。そこで、ISOでは、ISO 646のいくつかの番号を、その国固有の文字で入れ換えてよいことにした。一部の文字を入れ換えた各国語版のISO 646は、その国の中だけで使う分にはいいが、多国語環境では文字化けが起こる。「Ça est là.」というフランス語は、ドイツ語版では「Öa est l§.」に、日本版では「\a est l@.」に化けてしまう。
ISOでは各々の文字コードに識別番号をあたえ、その文書がなんの文字コード(コード表)で符号化されているかを明示するようにした。文書の最初や、言語が変わる位置にコード表の識別番号を置くことで、ここからはなんというコード表を使っているかを明示し、文字化けが解決する。
さまざまなコード表を切り換えて通信するためには、文字コードが同一構造をとっていなければならない。この構造と切り換え方法を定めたのがISO 2022という規格である。なお、フランス語やドイツ語ではISO 646の自国語版は情報交換用に使うだけで、内部処理は独自の内部コードを使うのが普通だった。
日本のJIS X 0201はISO 646の日本版(「\」を「\」に置きかえている)と、カタカナ(いわゆる「半角カナ」)文字セットをISO 2022で符号化した文字コードの二本立てで出来ている。インドのIS 13194はデーヴァナーガリー文字、タミル文字、ベンガル文字等々、インドで公用文字として認められている十の文字セットをISO 2022の構造に流しこんでいる。世界の文字コードで国家規格となっているもののほとんどはISO 2022にもとづいて作られている。
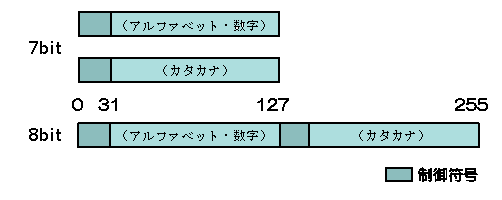
ISO 2022では7bitを二階建てにして8bitにできるようにするとともに、7bitないし8bitを複数組みあわせて、漢字のような巨大な文字セットを符号化できるようにしている。漢字を符号化したJIS基本漢字は、文字セットの段階では「区点番号」と呼ばれる1〜94の番号を二つ組みあわせることで、漢字一文字をあらわしている。
ISO 2022の2バイト・コードでは94x94=8836字までの文字を収録できるが、JIS基本漢字の場合、ユーザーが自分で文字をわりあてる外字エリアや、将来の拡張のためのエリアがあけてあるので、実際には6879字(漢字は6349字)しか収録していない。
ISO 2022も、その元になったASCIIも、本来、情報交換用に開発されたが、内部処理用(内部コード)にも流用されるようになった。英語だけの環境なら、それでも問題はないが、他の言語や多言語環境では、本来の用途と異なるだけに、テキスト処理が複雑化してしまう。
ISO 2022系文字コードを内部処理に使うと、ある文字列を複写する場合、そのコードがなんという文字コード(コード表)で符号化されたかを確認するために、前方に遡って識別番号を探さなければならない。複写した文字列を貼りつける場合も、貼りつける位置の文字コードがなにかを確認し、貼りつける文字列の文字コードが違っていたら、識別番号で文字コードを切り換えてから貼りつけ、さらに元の文字コードにもどしておかなければならない。検索や置換の場合も同様である。これを「状態をもつ」という。
最近のLinux人気でパソコン・ユーザーにも利用者の増えたMuleという多言語エディタでは、ISO 2022系の文字コードが混在した文書(「コンパウンド・テキスト」という)を読みこむ際、すべての文字の頭に識別番号をつけた内部コードに変換する。郵便にたとえると、国内に手紙を出す場合、「東京都千代田区……」のように宛名を書くが、Muleの内部コードではすべての宛名の前に「日本国」をつけ、「日本国東京都千代田区……」のように国名を明示するのである。これをリーディング・キャラクタ方式という(注1)。
宛名にいちいち「日本国」をつけていてはメモリ効率が悪くなるが、メインメモリは16Mバイトもあればすいすい動く。今日ではメモリがあり余っているので、16M程度では多いとはいえない。また、32bit固定長の内部コードに変換してから処理する方法を実装しているシステムもある。
1980年代まではメモリは貴重品で、リーディング・キャラクタ方式や32bit内部コード方式のような解決法は取りにくかった。ISO 2022をそのまま内部コードに使うケースがすくなくなく、ISO 2022は使いにくいという誤解が広まったが、現在の桁違いのメモリを考えると、解決の方向は見えたといえる。
シフトJISはアスキー・マイクロソフト社が開発したパソコン用内部コードである。ローマ字と「半角カナ」を二階建てにしたJIS X 0201の隙間に、JIS基本漢字の文字セットを流しこみ、コード表切り換えを不要にしたわけだ。日本語専用の内部コードとしてなら実にすぐれた設計で、他の漢字文化圏諸国の文字コードに影響をあたえたが、ディスクに書きこむ際にまでシフトJISを使ったために、混乱が生まれた。シフトJISはパソコンで多用されたが、さまざまなバリエーションが生まれ、互換性が怪しくなっていた。また、他の文字コードと区別できないので、日本ではフランス語やドイツ語、中国語、韓国語が扱えない状態がつづいた。
ユニコードは、ユニコード・コンソーシアムという業界団体が開発した内部コードだが、多くの言語で簡単にローカライズできるように工夫してある。ISO 2022は各言語の文字を収録した同一構造のコード表を次々と作っていくことで多言語に対応しているが、ユニコードは大きなコード表を一つ作り、その中に世界各国の文字をまとめて詰めこんでいる。
大きなコード表といっても、ユニコードの基本設計がまとまった1980年代後半の技術水準では16bit(256x256=6万5536字)がせいぜいだった。世界中の文字をこの限られたスペースに詰めこむために、形の似ている文字は一つにまとめることにした。これが文字統合である。
文字統合は漢字が有名だが、表音文字についてもおこなわれた。ISO 2022では基本アルファベット26文字は各国の文字コードに重複して収録しているが、ユニコードでは基本アルファベットは共通に使い、各言語固有の拡張アルファベットを追加している。アラビア文字でも、同じことをおこなっている。アラビア文字は、原則として母音を表記しないアラビア語のためにできた表記体系だが、母音表記が必要なインド・ヨーロッパ語族のペルシャ語、ウルドゥー語、アルタイ語族のウィグル語などでも使われている。ユニコードでは基本アラビア文字は共通に使い、ペルシャ語やウルドゥー語等で使う拡張アラビア文字を追加している。
その一方、記号類については統合せずに無秩序にいれている。日本でもそうだが、記号類は公的規格にはいっているものだけでは足りないので、コンピュータ企業は独自に追加する傾向がある。それが片端からはいっているのである。たとえば、空白は幅と機能のバリエーションで、なんと19種類もある。「-」もマイナス記号、ハイフン、ダッシュ、もしくはどれともつかないものなど、11種類がある。
伊藤隆幸氏が指摘するように、ユニコードの記号類を他の文字コードに変換するコード表は、コンピュータ企業によって微妙に異なる可能性があり、データをやりとりしているうちに、記号がすりかわってしまうという事態もなくはない。
ユニコード批判の急先鋒だった坂村健氏の論点が収録可能字数の制限、漢字統合、無秩序な記号収録、ISO 10646の強引な制定過程の四点に限られていたために、漢字問題ばかりがクローズアップされてきたが、実はユニコードはもっと深刻な難点をかかえている。早稲田=大谷大の多言語環境プロジェクトを推進する片岡裕氏が指摘するように、多言語処理では表音文字の統合の方が問題なのだ(注2)。
インド=ヨーロッパ語系のペルシャ語、ウルドゥー語、アルタイ語系のウィグル語等の文字は、アラビア文字を起源としているが、新しい文字を追加したり、文字の用法を買えていたりして、表記体系はまったく別物である。
セム語系のアラビア語の特性のために、アラビア文字は通常、母音を表記しない。ネイティブ・スピーカーは一まとまりの文字を見て、単語を認識し、無意識に三つある母音のどれかを補って読むのである。たとえば、「山」を意味する「ジャバル」は下図のようにつづる。右から順にj、b、lにあたる文字がならんでいる。

アラビア文字は当の単語を知らなければ発音できないので、表語文字(logogram)という。乱暴な喩えだが、漢字に近いところがある。
しかし、神の言葉とされる「コーラン」は、モハメッドの朗唱した通りに読まなければならないので、a、i、uにあたる母音記号やさまざまな補助記号を子音の上下につけて発音を特定しており、結合音節文字的性格を強めている。子供や外国人の学習用には、コーランの記法を転用した母音・補助記号つきのテキストが提供されている。先ほどの喩えにもどるなら、ルビつきの漢字に近いかもしれない。上にあげた「ジャバル」に母音記号を付加すると、下のようになる。

独立した母音をあらわすには、アリフ(![]() )にハムザ記号(
)にハムザ記号(![]() )を介して母音記号を付加するが、アルタイ語系のウィグル語では母音ではじまる語が多く、e、oにあたる単独の母音字を追加しており、音節文字的性格の強いアラビア文字は音素文字化している。ハムザ記号(
)を介して母音記号を付加するが、アルタイ語系のウィグル語では母音ではじまる語が多く、e、oにあたる単独の母音字を追加しており、音節文字的性格の強いアラビア文字は音素文字化している。ハムザ記号(![]() )は、ウィグル語では音節の区切をあらわす記号として使われており、ウィグル語の正書法の不可欠な要素となっているのだ。
)は、ウィグル語では音節の区切をあらわす記号として使われており、ウィグル語の正書法の不可欠な要素となっているのだ。
なぜ音節の区切をあらわす必要があるのだろうか? 日本語に引きつけて説明すると、「潤一郎」を「Junichiro」とローマ字表記した際、「ジュニチロー」か「ジュンイチロー」かわからなくなる。一部では「Jun'ichiro」のような表記が使われているが、ハムザ記号はこの「'」にあたる。アラビア語の表記体系におけるハムザ記号と、ウィグル語の表記体系におけるハムザ記号は起源と字形が同一であっても、実質的には別の文字であり、統合してしまっては多言語処理ができなくなる。ペルシャ文字、ウルドゥー文字も同様である。これに類した問題をかかえる表記体系は多く、多言語処理研究の重大な課題となっている。
世界中の文字の字形カタログを作れば、多言語処理ができると思うのは早計であって、せいぜい多言語表示ができるにすぎない。ユニコードのようにアラビア文字起源の文字をひとまとめに統合してしまうと、何語かわからなくなり、アラビア語とペルシャ語、ウルドゥー語の共存はもとより、表示さえ怪しくなる(ベンダー間の互換性を考えた場合)。ISO 2022系の夫々の文字コードを分離するという設計思想がここで生きてくる。
デーヴァナーガリー系の結合音節文字では別の問題が出てくるが、紙幅が限られているので、ここでは述べない。興味のある方は、『本とコンピュータ』1999年春号の拙稿「多言語処理はどこまで可能か」を御覧いただきたい。
漢字のコンピュータ化は難しいといわれるが、単に文字数が多いだけであって、量の問題さえ解決できれば比較的容易といえる。本当に困難なのはデーヴァナーガリー系やアラビア系の表記体系であり、真の多言語環境を構築するには、こうした表記体系を処理する構造を最初から設計に組みこんでおかなくてはならない。
片岡裕氏を中心に早稲田大・大谷大で開発を進めているSystem1という多言語環境はX11R5の国際化機能を拡張したもので、現在、実証段階は終わり、実用バージョンに着手しているという。片岡氏のチームは、当初は早稲田の外国人留学生に助力をあおいでいたが、その人的ネットワークが発展し、世界各地に協力者をうるにいたったという。中国については、中国社会科学院の協力のもとに、中国政府の正式許可をえて、新疆と雲南で数次にわたる調査をおこない、現地でなければえられない少数民族の表記体系の情報をえている(「ICMTP'98レポート」)。
ユニコードとISO 10646のややこしい関係は別稿にゆずるとして、ユニコード・コンソーシアムは普及のために各国の文字追加要求を受けいれていったために、16bit(65536字)ではパンクすることが明白になった。ユニコード・コンソーシアムではサロゲートペア(代理ペア)という仕掛で、約百万字を収用できるスペースを増築することにした。
サロゲートペアはユニコードの16bit符号を二つ組みあわせた32bitで一文字をあらわす。ユニコード符号のうち、55296〜56319までの1024個の符号をペアの前半に、56320〜57343までの1024個の符号をペアの後半に使う。1024x1024=104万8576字だが、これは16bit(65536字)文字面16面分にあたるので、文字コードの議論では32bitコードそのままではなく、UCS4の第1面から第16面に見立ててあつかう(もともとのユニコードはUCS4第0面にあたり、Basic Multi-lingual Plane=基本多言語面と呼ばれる)。第1面は表音文字、第2面は漢字、第14面は制御文字、第15、第16面は外字のエリアになる予定という。
ユニコード・コンソーシアムは言語や字体を特定するために、第14面の制御文字を使って、言語指定コードと字体指定コードを埋めこむ機構を検討しているが、この仕組が実装されるまでの間に、言語指定をふくまないデータがおびただしく蓄積されるだろう。文字コードの場合、一旦、中途半端な規格が広まると、後々禍根を残すのだが。
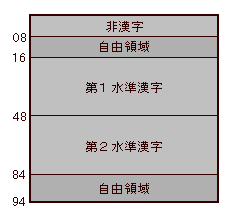
JIS X 0213と呼ばれることになる新しいJISコードの最終案は、記号類661字、漢字3685字、合計4383字を収録している。当初、5000字といわれていたが、一部のソフトで誤動作を引きおこす怖れのある番号をはずした結果、収録可能な文字数は4438に減り、そのうちの4383に文字をわりあてた。4383字は第3水準1910字と第4水準2436字にわかれる。空いている番号が55字分あり、第3水準非漢字エリア37、第3水準漢字エリア10、第4水準漢字エリア8で、漢字はわずか18字しかあいていない。空き番号はすべて「予約」となっており、外字登録は禁止されてある(それでも外字登録ツールを作って公開する人は出てくるだろうが)。
追加文字は、記号類では50までの丸つき数字、10までの二重丸つき数字、20までの黒抜き丸つき数字、丸つきカナ、丸つきアルファベット、天気記号、çのような拡張アルファベット、IPA国際字母(発音記号)、ローマ数字、トランプマーク、「(株)」のような約物、アイヌ語の表記に使われる「![]() 」のような拡張仮名がある。
」のような拡張仮名がある。
約物や丸つき数字、ローマ数字などは今まででも使えたじゃないかと思う人がいるかもしれないが、ベンダーのシステム外字として使えただけで、文字化けのおそれがあった。こうした記号類が情報交換に使えるようになるのはありがたい。
「現代日本語を表記するために必要な漢字」を網羅するという方針のもとに、1983年の改正で消された「鷗」や「瀆」が復活し、JIS基本漢字では包摂されていた「德」や「![]() 」のような人名用漢字表の許容字体や康煕別掲字も、別字として収録されている。地名などに使われる国字と「
」のような人名用漢字表の許容字体や康煕別掲字も、別字として収録されている。地名などに使われる国字と「![]() 」、「
」、「![]() 」のような主要部首がはいっている点である。これまでは部首に言及する場合は「クサカンムリ」、「シンニョウ」と書かなければならず、わかりにくかった。高校の教科書を調査し、漏れている漢字を採録した点も重要である。
」のような主要部首がはいっている点である。これまでは部首に言及する場合は「クサカンムリ」、「シンニョウ」と書かなければならず、わかりにくかった。高校の教科書を調査し、漏れている漢字を採録した点も重要である。
大半はユニコードにふくまれているが、三百字以上、未収録の漢字があり、日本提案として追加を申請するという。
最近のソフトは内部処理をユニコードでおこなうとされるものが増えている。そうしたソフトにシフトJISのデータを読ませたり、貼りつけたりすると、自動的にユニコードに変換されるが、ユニコードにはいっていない三百字余については、変換のしようがない。将来的にはユニコードにはいるとしても、それまでの期間、混乱が生ずるだろう。
文字数はどのように決まったのだろうか。下図を「シフトJISの構造」の図と見くらべていただきたい。
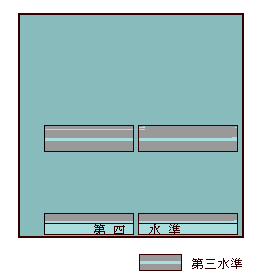
JIS基本漢字は94x94の文字面(8836字収録可能)に6879字を収録していることはすでに述べた。記号エリアと漢字エリアの間とか、第一水準漢字と第二水準漢字の間、第二水準漢字の後に1957字分(=8836-6879)の空きがあるのである。このうち、13区までの空きに記号類661字を、14区以降の空きに第3水準漢字1249字を詰めこんだわけだ。以上の文字は、従来のJIS漢字の隙間に入りこんで一体化するので(シフトJISでも同様)、大半のメーラーでそのまま送れると思われる。
第4水準漢字の2436字はISO 2022とシフトJISであつかいが異なる。ISO 2022では従来のJIS漢字とは別の94x94の文字面に収録される。94x94の文字面には8836字収録可能だが、2436字しか配置しないのはシフトJISの制限のためである。シフトJISの第一バイトはJISローマ字・カナの「半角カナ」を避けているが、255までの番号のうち、239までしか使っておらず、240以降が空いている。ここをフルに使えば、3008字が収録できるが、ハイアドレスは一部のソフトが制御用に使っているために、異常動作のおそれがある。そこで2444字分だけを使い、そのうちの8字分を予約にし、2436字を収録したわけである。いずれにせよ、現在のメーラーではまったく送れない。
ISO 2022では第一〜第3水準までを配置した第一面と第4水準を配置した第二面を切り替える必要があるが、シフトJISでは一面にちょうどおさまっているので、フォントを入れ換えるだけで、WindowsでもMacintoshでも、1万字余に増えた新しいJIS基本漢字を使うことができる。まことにめでたい話とひとまずは喜びたい。
だが、薬に副作用がつきものなように、今回の拡張にも深刻な混乱が予想される。構造的な文字化けが起こるのである。
記号類と第3水準漢字を配置しているエリアは、一部のワープロ専用機が外字エリアに使っているし、第4水準漢字のエリアはWindowsやMS-DOSの外字エリアとそっくり重なっている(Macintoshも以前はここを外字エリアに使っていた。現在でも非公認の外字ツールが出回っている)。外字はすべて文字化けするのである。
外字を登録していないという人も安心できない。ベンダー側があらかじめ組みこんだたシステム外字を知らずに使っていることがよくあるからだ。特に深刻なのはWindows外字である。
Windows外字はNECとIBMのシステム外字をマイクロソフトが踏襲したもので、『エンカルタ』でも使われているが、「NEC拡張記号」起源の記号類と、「IBM拡張漢字」起源の漢字・記号類にわかれる。「NEC拡張記号」起源の記号類は、今回の追加ではできるだけ位置を踏襲するように配慮されているので比較的弊害が少ないが、「IBM拡張漢字」の方は問題が多い。
Windowsをお使いの方はSystemフォルダーの中の「文字コード表」を起動してほしい。標準ではフォント名が「MS明朝」になっていると思う。「種類」が「すべて」になっていることを確認し、コード表をどんどん先に進んでほしい。JIS基本漢字の最後の「熙」のうしろに「・」が延々とつづいているはずだ。0xED40(十進数で60736)までいくと、「![]() ……」と新たに漢字列がはじまっているだろう。これがNEC外字で、今回、追加される第3水準漢字の一部と重なっている。次にまた「・」がつづくが、0xFA40からローマ数字、「(株)」などの約物につづいて、また「
……」と新たに漢字列がはじまっているだろう。これがNEC外字で、今回、追加される第3水準漢字の一部と重なっている。次にまた「・」がつづくが、0xFA40からローマ数字、「(株)」などの約物につづいて、また「![]() ……」にはじまる漢字列がつづく。こちらがIBM外字で、第4水準漢字の一部と重なっている。
……」にはじまる漢字列がつづく。こちらがIBM外字で、第4水準漢字の一部と重なっている。
IBM外字は大型機由来の「IBM拡張漢字」388字を収録したもので、漢字は360字ある。NECはIBM外字のすべての漢字と、「NEC拡張記号」にない記号14字を、IBM外字とは別の位置に収録した。マイクロソフト社は互換性を考慮し、重複をいとわず、この両方を元のままの位置に収録している。人名に使われる「彅」、「![]() 」、「弴」、「髙」、「靑」、「閒」、「
」、「弴」、「髙」、「靑」、「閒」、「![]() 」、「橫」、外国人名に使われる「鄧」、「燁」などがはいっている。インターネットでは使えないものの、LANやメールに添付するワープロ文書の中でなら使えるので利用者が多い(Windows外字に対応している別売フォントもある)。これが化けまくるのである。
」、「橫」、外国人名に使われる「鄧」、「燁」などがはいっている。インターネットでは使えないものの、LANやメールに添付するワープロ文書の中でなら使えるので利用者が多い(Windows外字に対応している別売フォントもある)。これが化けまくるのである。
「草![]() 」は「草
」は「草![]() 」もしくは「草
」もしくは「草![]() 」に、「山
」に、「山![]() 」は「山
」は「山![]() 」もしくは「山
」もしくは「山![]() 」に、「里見
」に、「里見![]() 」は「里見
」は「里見![]() 」もしくは「里見
」もしくは「里見![]() 」に化けるだろう。逆にJIS X 0213で書いた「山
」に化けるだろう。逆にJIS X 0213で書いた「山![]() 」は現行フォントでは「山
」は現行フォントでは「山![]() 」に化ける(注3)。
」に化ける(注3)。
すべての人が一斉に新しいJIS漢字対応フォントに入れ換えるなどということはありえないし、フォントを入れるだけでいいといっても、できない人もいるだろう。ちょっと古いパソコンや電子手帳だと、入れること自体できない。また、JIS X 0213対応フォントを入れれば入れたで、過去のデータが化ける。変換ソフトを作って配ればいいと思うかもしれないが、「![]() 」、「
」、「![]() 」、「
」、「![]() 」などは、Windows外字にはいっているにもかからず、今回、別字として収録されなかったので、変換のしようがない。「徳」と「
」などは、Windows外字にはいっているにもかからず、今回、別字として収録されなかったので、変換のしようがない。「徳」と「![]() 」、「隆」と「
」、「隆」と「![]() 」が別番号なのに、「高」と「
」が別番号なのに、「高」と「![]() 」、「間」と「
」、「間」と「![]() 」が同一番号に包摂というのも妙な話である。利用者の多いWindows外字ぐらいはすべて入れるべきであろう(85字も落ちているので、最終案でははいりきらないが)。
」が同一番号に包摂というのも妙な話である。利用者の多いWindows外字ぐらいはすべて入れるべきであろう(85字も落ちているので、最終案でははいりきらないが)。
高校の教科書の漢字を網羅するとしながら、漢文の返り点がはいらなかったのも理解に苦しむ。「![]() 」のような教科書特有の字をいれるのも結構だが、漢文は一種の翻訳であって、日本文学の一部であり、現在も多くの人に親しまれている。記号類をいれる場所はまだ37字分も空いているのだから、十分収録可能なはずである。
」のような教科書特有の字をいれるのも結構だが、漢文は一種の翻訳であって、日本文学の一部であり、現在も多くの人に親しまれている。記号類をいれる場所はまだ37字分も空いているのだから、十分収録可能なはずである。
図書館など、データの厳密な一貫性が求められる分野では、1983年改訂で廃止されたはずの1978年版JISをまだ使っているが(厳密にいえば、法律的に問題がある)、JIS X 0213はJIS基本漢字(JIS X 0208)の改訂ではなく、あくまで別規格なので、6千8百字の現行のJISコードと1万字の新しいJISコードは、将来にわたって併用されるはずである(法律的にはまったく問題ない)。
構造的文字化けについて、JCS委員会側は「指定席券がないのに指定席に座っている場合に、指定券を持っている人が来たら席をあける必要があるのと同じことである」と書いているが(JCS調査研究委員会の「この規格の考え方について」参照)、1997年までは外字が禁止されておらず、いわば自由席だったことを考えると釈然としない人もすくなくないだろう。Windows98には外字登録ツールと、Windows外字を収録したフォントが依然として装備されており、自由席状態がつづいているし、来年、日本語版の出るWindows2000でも事情は変らないらしい。そもそも、1997年の禁止からわずか三年で新しい文字をいれた文字コードを施行すること自体に無理があるのだ。
JIS X 0213原案は11月のはじめに、二ヶ月間にわたる長期審議の末に可決されたが、器にあたる符号化形式について、留保条件がついた模様である。
文字コードと文字セットの違いは最初に述べたが、新しい文字コードを作ろうとすると複雑な問題がからんでくるので、符号化を棚上げし、ひとまず文字セットだけを作ろうという動きが進んでいる。コードがふられていなくては、コンピュータで使えないのではないかと思うかもしれないが、フォントが無償公開されていれば、お互いに共通のフォントを共有でき、そのフォントにおける通し番号を伝えることで、どの文字かが特定できるのである。研究者の間では諸橋轍次の『大漢和辞典』の検字番号でJIS表外字を特定する方法がかなりおこなわれていたが、そのフォント版といえる。
変則的だが、多くのCD-ROM出版物のように、JIS表外字をマッピングした「裏フォント」を使う手もあるし、XMLの実体参照でも文中に表示することができる。ただし、どちらも検索や置換といったテキスト操作はできない。
「今昔文字鏡」はもっとも早く1986年からはじまったプロジェクトで、エーアイネットの古家時雄氏が漢字学、中国文学、国文学、仏教学、歴史学など、さまざまな分野の研究者の支援のもとに、13年がかりで構築したフォントを公開している。漢字データベース部分は紀伊国屋書店から製品として販売されているが、漢字八万字、非漢字一万字を収録したTrueTypeフォントと簡易検索ソフトは、石川忠久氏を会長とする「今昔文字鏡研究会」(注4)に百年間の契約で配布権をゆだね、無償配布をおこなっている。ホームページでは文字鏡文字の画像(24ドッと版と96ドット版)も無償公開し、使いたい文字画像のURLを書きこむことで、利用者のWWWページに文字鏡文字を表示することができる。
「文字鏡」が学会で知られるようになると、外字問題で苦しんでいた若い研究者たちは文献から採取した漢字の資料と最新の漢字学の知見を提供し、プロジェクトを支援するようになった。1997年からは松丸道雄氏の指導による甲骨文、兒玉義隆氏の指導による梵文のフォント化に着手し、メコン・センターの杜聡明氏の要請により字喃(ベトナムの国字)のフォント製作がはじまった。現在、西夏文字、水文、六十四卦、源氏香等がはいり、漢字文化圏のあらゆる文字を収集するという所期の目標に近づいている。「文字鏡フォント」はMacintosh版、TeX版、PS版がすでに公開されており、近々、Muleでも使えるようになるという。
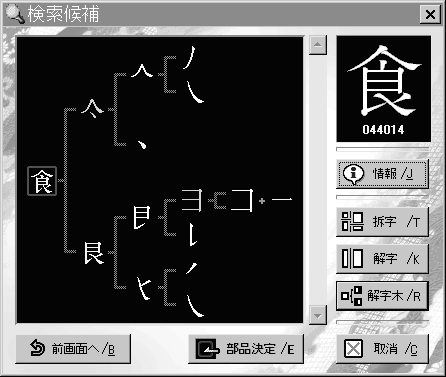
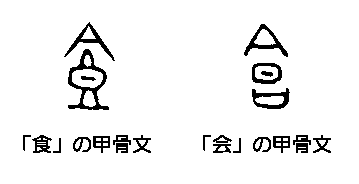
「今昔文字鏡」のデータベースは、漢字を部首以下のレベルまで分解する解字という手法で作られており、漢字の論理的生成を解字木というツリー形式で見ることができる。図は「食」の解字木である。「![]() 」と「良」ではなく、「
」と「良」ではなく、「![]() 」と「艮」に分かれるのは、「食」の甲骨文に明らかなように、蓋をかぶせた
」と「艮」に分かれるのは、「食」の甲骨文に明らかなように、蓋をかぶせた![]() という食器を象っているからである。「食」とは
という食器を象っているからである。「食」とは![]() にいれた食物のことなのである。
にいれた食物のことなのである。
「![]() 」は「会」の上半分でもある。「会」の正字は「會」だが、この甲骨文は甑に蓋(
」は「会」の上半分でもある。「会」の正字は「會」だが、この甲骨文は甑に蓋(![]() )をかぶせたさまを象っている。器と蓋がぴったり合うところから、「会う」という意味が生まれた。解字木は中国五千年の文字の歴史の深部に降りていく大変なツールで、使いこめば使いこむほど興味が深まっていくが、Windowsで動く製品版だけの機能で、他のプラットホームに移植の予定はないという。
)をかぶせたさまを象っている。器と蓋がぴったり合うところから、「会う」という意味が生まれた。解字木は中国五千年の文字の歴史の深部に降りていく大変なツールで、使いこめば使いこむほど興味が深まっていくが、Windowsで動く製品版だけの機能で、他のプラットホームに移植の予定はないという。
「e漢字」は「いーかんじ」と読む。京大人文科学研究所の勝村哲也氏と丹羽正之氏が推進しているプロジェクトで、1997年10月にユニコードのCJK漢字2万字余の24ドットフォント(日本欄)を無償公開したのをかわきりに、京大が1981年に康煕字典の親字に通し番号を付けた『康煕字典文字集覧』準拠の四万九千字余、大漢和辞典の5万字余を次々と公開し、現在は世界最大の漢字字典『中華字海』8万7千字のフォント化にとりくんでいる。漢字を特定するには、大漢和辞典ならm、康煕字典ならkの後に検字番号をつけ、ユニコードならuの後に16進数をつける。
「e漢字」は歴史上あらわれたすべての漢字を網羅した単一文字セットを作るのは不可能という考えに立っており、あえて「e漢字」としての通し番号はつけず、代表的な辞書類を個別にカバーしていき、相互にリンクすることで、形・音・義のみならず、時代・地域を加味した多元的な漢字データベースを構築しようとしている。
異体字の時代的・地域的分布を記述しようにも、従来は異体字を分類する手法が確立していなかったので、記述のしようがなかった。勝村氏と丹羽氏は「漢字合成法」という漢字組成記述の文法を確立し、1994年に基本分割表『漢字典』として刊行している。「e漢字」は単なる無償フォント集ではなく、『漢字典』を土台として構築される多元漢字データベースであり、将来的にはフォントだけではなく、形・音・義と時代・地域分布を記述したデータベース部分もインターネットで公開する方向という。
「GTコード」は東大と学術振興会が1995年8月に、「産学協同支援事業」として、着手した「人文系多国語テクスト・プロセシング・システムの構築に関する研究」で作成しようとしている文字セットとフォントである(Gは日本学術振興会、Tは東大の頭文字)。当初は「東大明朝」と呼ばれていたが、「GT明朝」に変わり、現在は「GTコード」になっている。フランス文学の田村毅氏を代表に、委員にギリシャ・ローマ考古学の青柳正規氏、西洋古典学の片山英男氏、情報工学の坂村健氏の三氏、監修に国語学の山口明穂氏が名をつらねている。1996年からは「マルチメディア通信システムにおける多国語処理研究プロジェクト」という五ヶ年の事業として継続中である。
「GTコード」に関しては現物が出てきていないし、抽象的な理念程度しか情報が出てきていないが、もともとTRONプロジェクトの坂村氏の提唱で開発がはじまり、TRONコードの日本語拡張部分にはいることになっている。NTTや印刷会社、CD-ROM出版の外字セットなど、JISの委員会の収集範囲と重なる範囲から20万字を収集し、大手フォント・ベンダーの協力で6万4千字に整理したという。
「今昔文字鏡」と「e漢字」は学術用フォントの無償提供にとどまっており、高い印刷品位を要求される場合は無償フォントをサンプルにして、フォントデザイナーに外字作成を依頼することになる。これに対して、「GTコード」は国費で開発した学術用フォント二種(明朝体と教科書体)を無償公開する一方、フォント・ベンダーにライセンスし、商用フォントとして発売することが予定されている(「GTコード」の開発費の一部は国費を借りている形であり、いずれ返済しなければならない)。印刷会社が「GTコード」フォントを用意していれば、外字を発注しなくてもよくなるわけで、この点に「GTコード」の利点がある。
しかし、印刷に使える水準の商用フォントはもともと高額であり、6万字を越える大規模フォントを何種類かそろえなければならなると、小規模な組版業者にとっては死活問題になる。そのため、印刷関係の一部団体が激しく反発し、1997年の「GTコード」(当時は「GT明朝」といった)内覧会には、多数の組版業者とフォントデザイナーが詰めかけ、怒号とヤジのうちに進行した。「GTコード」批判はその後も執拗につづいた。「GTコード」側は批判を黙殺したものの、完成したフォントの公開は『GTコード・ブック』の完成後にもちこされた。
最後の「拡張CJK」はISO 10646とユニコードのCJK統合漢字を選定し、引きつづき同文字セットの保守にあたっている「絵文字連絡会」(CJK-JRGの後身)が準備している拡張版である。日中韓台香にくわえて、ベトナムも追加候補の漢字を申請している。
「拡張CJK」による拡張は、現在のところ、三期にわけておこなわれることが決っている。まず、BMP内の元のハングル領域に追加される「エクステンションA」の6837字で、この文字セットは来年前半に出版されるユニコード3.0に収録されるようだ。
BMPは「エクステンションA」で満杯になるが、サロゲートペアで拡張する第二面が、CJK統合漢字と同じルールで統合した漢字セット用に確保されている。同じルールといっても、JIS X 0213の関係の「康煕別掲字」、台湾のCNS 11643の三面以降にふくまれる異体字が検討の対象になるので、同じルールといっても、JIS X 0213の関係「康煕別掲字」、台湾のCNS 11643の三面以降にふくまれる異体字が検討の対象になるので、「大文字セット」的な性格(「小は大をかねるか?」参照)を強めると予想される。一面あたり約6万5千字が収録できるが、すでにデバッグの進んでいる4万726字が「エクステンションB」という名称で、来年後半に追加候補として発表されるようである。ここまでで7万字になり、「康煕字典」や「大漢和辞典」の漢字はすべて網羅される見こみである。
第二面にはまだ2万5千字近い空きがあり、そこにいれる漢字セットとして「エクステンションC」の準備がはじまっている(こちらはまだソースが決った段階である)。また、非公式にだが、CJK統合ルールによらない漢字セットを別の面にいれようという議論もはじまっているという。
1999年11月に発売される「超漢字」はBTRON3準拠の純国産32bitOS、Bright/V R2上に実装した多文字環境で、古今東西の文字、13万字の搭載をうたっている。
昨年発売されたBright/V R1は、「GT明朝」が間に合わなかった関係で、JIS基本漢字とJIS補助漢字(JIS X 0212)、中国のGBコード、韓国のKSコード、あわせて2万8千字の収録にとどまっていた。「GT明朝」あらため「GTコード」は今年も間に合わず、このまま来年をむかえていたら、「拡張CJK」の発表で、「超漢字」は出し遅れの証文になるところだった。しかし、「今昔文字鏡」と提携して、甲骨文字や水文、西夏文字等をふくむ9万字を収録し、ユニコードの漢字・ハングルを除く世界の文字6千字を追加したことで、からくも公約を果すことができたわけである。なお、ユニコードの漢字とハングルは、今回はフォントが入手できなかったので見送ったが、いずれ収録する予定という。
「超漢字」文字セットの七割を占める「文字鏡」文字セットはWindows、Macintosh、Unixなど、多くのプラットホームでサポートされているが、文字コードをふられていないために、表示やプリントアウトはできても、検索・置換などテキスト処理に制約があった(注5)。
TRONのプロジェクト・リーダーの坂村健氏は「世界中のすべての言語をフラットに取り扱える情報交換のインフラストラクチャ」をTRONで築くという理想をかかげ、「外字を必要としないシステムとする」、「全世界、古今東西のあらゆる文字を取り扱えるようにする」を金科玉条としていたが、TRONコードという器は用意したものの、中にいれる文字については、「GTコード」に参加した以外は、収集にかかわってはいなかった。いろいろ経緯はあったものの、TRONと「今昔文字鏡」が手を結んだことは、TRON、「文字鏡」双方にとってのみならず、ユーザーにとっても意義が大きいだろう。
大文字セットの実装には賛否両論がある。筆者自身は大文字セットの必要性を訴えてきたが、一般の人間にそんなに多くの文字は不要であるとか、システムとして破綻するといった批判の声も多かった。だが、必要論にせよ、不要論にせよ、破綻論にせよ、実際に大文字セットを実装したパソコンを使いこんで発言しているわけではなかった。そもそも、個人レベルで使える、大文字セットのシステムは存在しなかった。いきおい、議論は神学論争の様相を帯びざるをえなかったが、「超漢字」の登場でいよいよ大文字セットの当否が試されるわけである。
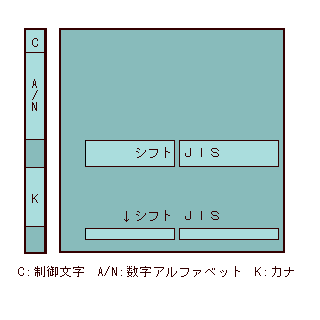
ここでBTRONの内部コードであるTRONコードについて見ておきたい。TRONコードは世界のさまざまな言語を表記するために、1バイトもしくは2バイトのコード表を作り、識別番号をつけて切り換えるという、ISO 2022とよく似た設計思想で作られていた。しかし、コード表(TRONでは言語面という)の構造は微妙に違い、世界中に厖大な蓄積のあるISO 2022系文字コードとの互換性はない。
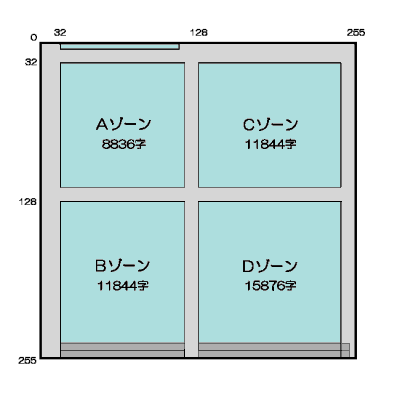
1バイトのコード表の場合、ISO 2022は7bitを二階建てにする関係で188ないし192字はいるのに対し、TRONコードでは220字はいる。これは制御符号の位置が違うからである。ISO 2022では0〜31と128〜159の64字分を制御符号にわりあてる。TRONコードでは0〜31は同じだが、128〜159の部分にも文字をいれ、かわりに254と255をBTRON独自の制御符号としている。2バイトのコード表は図を見ていただくとして、収録文字数は4万8400字である。
独自制御符号のうち、「254」は言語指定コードといい、コード表(言語面)をあらわす識別番号をつづける。「超漢字」の基本エディタには「原稿モード」、「詳細モード」、「清書モード」の三つの表示モードがあるが、「原稿モード」と「詳細モード」では言語面切替の識別番号が目視できでしまう。
識別番号となるのは、32〜125、128〜253の範囲の220個の番号である。コード表(言語面)が220面を越えた時は、「254」を二つつづけ、その後に識別番号をおく。440面を越えたら、「254」を三つつづけてから識別番号をおく。ISO 2022と似た方式でいくらでもコード表(言語面)を追加できるわけだが、太田昌孝氏のように、TRONコードにできることはISO 2022でもすべてできるのだから、新しい規格を作る必要はなかったのではないかという批判もある(注6)。しかし、TRONコードはBTRONの内部コードにすぎないのだから、問題にするにはあたらないと思う。
先頭の識別番号(32)は当初は「日本語スクリプト1」とされていたが、1B/V3の時代に「システム・スクリプト」に変更になり、中国のGBコード、韓国のKSコードを収録した。これを「とりあえず多言語環境」と呼ぶが、ユニコードにつぶされたISO 10646の最初の原案(DIS 10646 1.0)の「基本多言語面」によく似ている。
「とりあえず多言語環境」を第1面とすると、「超漢字」を期にTRONコードの1〜17面までの内容が決まった(別表参照)。実際に文字セットがはいっているのは、1面と6面、11〜14面、16面の計7面である。6面はBig5、11面から14面が「文字鏡スクリプト」、16面は漢字とハングルを除いたユニコードの文字セットで、「各国語スクリプト」と呼ばれる。
|
|
|
|
|
|
|
1
|
0xFE21
|
システムスクリプト | JIS基本漢字、JIS補助漢字
GB基本漢字(中国簡体字) KS基本漢字・ハングル |
|
|
2
|
0xFE22
|
日本スクリプト1 | 予約 | |
|
3
|
0xFE23
|
日本スクリプト2 | 予約 | |
|
4
|
0xFE24
|
中国スクリプト1 | 中国語簡体字の予約 | |
|
5
|
0xFE25
|
中国スクリプト2 | 中国語簡体字の予約 | |
|
6
|
0xFE26
|
中国スクリプト3 | CNS 11643の1・2面(中国伝統字) | |
|
7
|
0xFE27
|
中国スクリプト4 | 中国語伝統字の予約 | |
|
8
|
0xFE28
|
韓国スクリプト1 | 韓国文字の予約 | |
|
9
|
0xFE29
|
韓国スクリプト2 | 韓国文字の予約 | |
|
10
|
0xFE2A
|
未定 | 予約 | |
|
11
|
0xFE2B
|
文字鏡スクリプト1 | 『大漢和辞典』 | |
|
12
|
0xFE2C
|
文字鏡スクリプト2 | 『大漢和辞典』、文字鏡収集文字 | |
|
13
|
0xFE2D
|
文字鏡スクリプト3 | 文字鏡収集文字 | |
|
14
|
0xFE2E
|
文字鏡スクリプト4 | 予約 | |
|
15
|
0xFE2F
|
文字鏡スクリプト5 | 予約 | |
|
16
|
0xFE30
|
各国語スクリプト1 | ユニコード非漢字部分 | |
|
17
|
0xFE31
|
各国語スクリプト2 | ユニコード予約 |
TRONコードの文字処理機構は「言語層」、「文字属層」、「スクリプト層」、「フォント層」の四層構造モデルをとっている(現状の「超漢字」は完全に四層を実装しているわけではない)。
一番上の「言語層」はUNIXやWindowsでいうロケールにあたり、ソート順や日時、数値の表記規則のデータベースである。スペイン語など、ラテン系の言語では桁区切りの「,」と小数点の「.」が逆で、「2,000.35」を「2.000,35」のように表記するが、ロケールはこうした処理を切り換える機能である。Windowsなどでは当り前の機能であるが、現状の「超漢字」では日本語の表記規則しか実装していない。早急な対応が待たれる。
二層目の「文字属層」は文字列の編集をおこない、三層目の「スクリプト層」はドイツ語の「ss」という文字列を「ß」というグリフに結びつけるといったリガチャーの処理をおこなう。一番下の「フォント層」はCIDフォントのようなフォント・テーブルを含み、フォントの使い回しを可能にするという。テキスト処理にかかわるのは「文字属層」と「スクリプト層」で、実質的には二層構造と考えられる。
「超漢字」の最初のバージョンにつくメーラーはISO 2022-JPにしか対応せず、JIS表外字は〓になるという。TRONコードは既存文字セットをそのままTRONコードという器に詰めこんでいる。「とりあえず多言語環境」で記述した日中韓の混在テキストは、インターネットに送りだす際には、太田昌孝氏が策定したISO 2022-JP2というISO 2022のサブセットに変換可能だし、今回くわわった文字セットも、Big5はBig5ないしCNS11643で、ユニコードはUTF8で、「文字鏡」は文字鏡番号に直すことで送れるはずである。変換ツールの早急な整備を期待したい。
TRONコードは、もともと、各言語ごとにコード表(文字面)をわける方針だった。「とりあえず多言語面」には日中韓三ヶ国の文字がはいってはいるが、統合していないので、コード位置によってどの言語の文字かが判別できる。しかし、ユニコード文字セットの場合は、コード位置ではラテン文字か、キリル文字か、アラビア文字かといった文字の種類がわかるだけで、どの表記体系かはわからない。将来、各言語の文字セットを別々のコード表(言語面)に収録したとしても、一度いれた文字は将来にわたってサポートしつづけるのが文字コードの原則である。世界中の文字を収録するには、ユニコード文字セットをいれるのが一番簡単に思えたのかもしれないが、この選択は後々禍根を残すだろう(「超漢字」の多言語機能の実際については、近々掲載する使用感のページでふれる予定である。)。
今回、中国のGBコードにくわえて、Big5の文字セット(前に述べたように、CNS 11643の最初の二面に相当)がはいったが、中文IMEは中国語のわかる協力者がいなかったので今回は見送られ、従来からある「ピンイン入力小物」にとどまったという。大手のパソコンショップで入手できるAT互換機用のピンイン・キーボードや注音キーボードのサポートも課題として残っている。フランス語、ドイツ語など、ヨーロッパ言語のキーボードは、GTコードの関係で協力者がいたということで、すでに対応済みである。
一番残念なのは、異体字や中国伝統字、簡体字、韓国漢字を同時検索するためのシソーラス検索機能(曖昧検索機能)が先送りされたことである。シソーラス検索機能がないと、異体字の数だけ検索を繰りかえさなければならない。JIS基本漢字でも「渡辺」、「渡邊」、「渡邉」、「渡部」のような書きわけが可能なので、Wordのようなワープロは簡単なシソーラス検索機能をもっている。CD-ROM版『四庫全書』にいたっては、使用文字種数が3万字を越えるために、七つのレベルを設定できる高度のシソーラス検索機能を備えている(「『アジアの漢字と文献処理』レポート」参照)。11万字余の漢字を載せた「超漢字」ではCD-ROM版『四庫全書』クラスのシソーラス検索機能がなくては使いものにならない。次回バージョンアップなどと悠長なことはいわず、一日も早い実装を要望する。
ISOのコンピュータ関係規格制定活動の日本側窓口であり、歴史的にも文字コード問題に深くかかわってきた情報処理学会情報規格調査会は、棟上昭男会長の提唱で、1999年2月に「文字コード標準体系検討専門委員会」(以下、「棟上委員会」とする)を設置し、ISOの文字コード制定活動に対する日本の方針を討議し、8月に5項目の提言をまとめた。
棟上委員会は広く各界に参加を呼びかけた結果、各省庁からはもちろん、従来、コンピュータ関係の委員会に縁のなかった日本ペンクラブや日本文藝家協会からも委員が出ている。これだけの顔ぶれが集まったこと自体、画期的といえるが、互いの基本的認識のズレが明らかになったことも意義が大きい。棟上委員会では、価値判断が混じりがちな「異形字」を「異形字」、字形の揺れの範囲を「粒度」とするなど、用語の見直しからはじめている。
棟上委員会は、技術的見地からはISO 2022の方がISO 10646よりもすぐれているという意見が多いとしながらも、ユニコードへという大きな流れができつつある現状をふまえ、ISO 10646の改良という形でISOの場で日本の主張を提案していく方針を打ちだしている。
紙幅が尽きてきたので、最後に棟上委員会の提言を要約し、簡単な解説をくわえよう。
1の「分散開発」だが、すでに実用範囲での文字のコード化は終わっているので、今後は僻字や古代文字、少数民族の文字などに収録の重点が移っていくと考えられる。こうした特殊な文字は、ISOやJISの委員がにわか勉強しても対応しきれないので、専門の研究者や学術団体の提案した文字セットを追認していこうということである。
3と4はISO 10646(=ユニコード)の将来像に言及しており、特に注目したい。ISO 10646の設計思想では、テキスト処理の対象である「文字」(キャラクター)と、具体的な図形として実現される「字形」(グリフ)をわけているが、区別は徹底したものではなく、「fi」を一文字とした「字形」を「文字」として登録している。活版印刷の現場では「fi」を一つに鋳造した活字を使ってきた歴史があるが、組版の都合にすぎず、実際は二文字である(リガチャーとするのは誤り)。ISO/IEC tr15285というテクニカル・レポートは、こうした混乱がふたたび起こらないように、「文字」と「字形」を峻別するモデルを提案し、ISO 10646の理論的支柱として承認されている。
だが、この文書は「文字は意味ないし音声における差異を伝える。文字は固有の形状を有さない」とあるように、音標文字の発想を基本としており、漢字のような表音文字にはあわない面がある。特に、このモデルを厳密に適用すると、異体字は新しい文字種として収録できないおそれがある。そこで、ISO/IEC tr15285改訂の提案を明記したわけである。
5は市場性のない文字も、文化の観点から収録するように働きかけていこうということで、正論である。
いずれの提言も重要なものであり、21世紀におよぼす影響ははかりしれない。報告書は情報規格調査会の「文字コード標準体系検討専門委員会」のページで公開されているので、文字コードに関心のある方はぜひ一読されることをお勧めする。