「文字コード問題早わかり」は1996年11月に「カタカナ篇」をかわきりに順次公開し、翌年3月の「ユニコード篇」で一応の完結を見ました。
その後、『電脳社会の日本語』の取材のために関係者に直接お話をうかがったり、関連資料の収集につとめたところ、多くの新事実を発掘するとともに、通説の誤りも見つかりました。本ページにも多くの誤りがありますが、直すとしたらゼロから書き直さなければならないので、内容の更新は1998年5月を最後におこなっていません。
本ページは引きつづき参考として公開をつづけますが、文字コードの歴史に興味のある方は拙著『電脳社会の日本語』(文春新書)をお読みください。(2000年 4月 7日)
なお、以降、「文字コード問題早わかり」は一切更新しません。(Apr07 2000)
「iモード絵文字という悪夢」の「これでは普及するのは当り前ですね。」の後に「今後の展開としては、TVのセットトップボックスが考えられるでしょう。TVによるインターネット接続は、画面解像度の低さがネックになって、今一つ進んでいませんが、iモード向けページ閲覧を主眼にした売方をすれば、解像度の問題はクリアできます。」を追加しました。(Mar01 2000)
字数の誤りもあるのですが、JIS X 0213の規格票が発行されてから一括して直すことにして、今回は手を触れていません。(Feb28 2000)
(Jul28 1999)
78JISの委員名簿を再度確認したところ、西村恕彦氏のお名前が掲載されていました。主査だから上の方に載っているに違いないという先入見があったのですが、この時の委員会は主査はおかなかったようです。西村氏が主査的な役割(規格票本文と解説の執筆)を果たされたことは、近々公開のインタビューに言及があります。また、矢島敬二氏が委員として参加したのではないことは「漢字・アラビア文字・モンゴル文字」で明らかになりました。以上、ご迷惑をおかけした西村恕彦氏、矢島敬二氏にお詫びするとともに、訂正いたします。(May30 1999)
工業技術院では、現行JIS基本漢字の例示字形を変更するなどという無茶は避け、必要な字体を、別の文字として新拡張JISに登録する方針と聞く。
これは英断と評価できる。なぜ英断かといえば、JIS X 0208:1997の字体包摂の思想にしたがう限り、「なにもしない」という対処法しかないからである。
78JISの「」と83JISの「堋」は52-36という区点位置に包摂されており、互いに区別されないとするのが、JIS基本漢字第四次規格の考え方である。逆にいえば、52-36は「
したがって、52-36が「
区別しないなら、例示字体を変えてもいいように思うかもしれないが、例示字体はあくまで例示であって、規範的に受けとめられてはならないというのが、97JISの考え方で、規格表にもくりかえし明記してある。例示字体をあえて変更したら、その字体に規範的性格があることを認めてしまうことになるのである。この点もふくめて、なにもしなくても「表試案」にすでに対応しているというのが 97JISの考え方といってよい。
それゆえ、「
問題は Unicodeである。JISだけだったら、工業技術院の判断で英断も可能になるのだが、Unicodeは欧米の企業を中心に構成されるユニコード・コンソーシアムに決定権がある。形が似ていて統合すべき文字でも、元(ソース)の規格で別字とされている文字は統合しないという原規格分離漢字規則がルールとしてあるが、台湾のCNSコードの新しい拡張は、このルールからはずされており、日本側の文字追加申請がそのまま通るという保証はない。
追加が認められたとしても、これからはいる漢字はサロゲートペアによる拡張になってしまう。サロゲートペアの実装は、来年、出てくる Unicode3.0で規定されるが、対応するOSが登場するのは、相当先になるであろう。また、すべてのアプリケーションがサロゲートペアに対応する保証もない。
おそらく、Unicodeの場合、標準フォントを「印刷標準字体フォント」に入れ替えることよって、対応するものと思われる。Unicodeは JIS基本漢字第四次規格よりもさらに大雑把な包摂(文字統合)をおこなっており、「堋」でなく「
もっとも、Unicode製品を発売しているあるベンダーの担当者にこの話をしたところ、あきらかに狼狽していた。Unicode推進派の人々は、字体の違いはフォント切替などでいくらでも対応できると宣伝していたが、本当に別の字体のフォントを実装するようなことになるとは考えていなかったらしい(ユーザーが納得しないだろう)。
Unicode製品ベンダーが、従来の宣伝通りフォントで対応するか、それともXKPに逃げるか、おもしろいことになりそうである。
- 「褐」はJIS78では当用漢字に準じた字体を採用していましたので、「略字体に直す必要がある」文字からはずします。
- JIS78の「
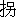 」は俗字で、JIS83の「拐」の方が伝統的字体なので、「伝統的字体」に直された文字に移します。これにともない、「一部の表外字が略字体で例示され」を、「一部の表外字が略字体・俗字体で例示され」と改めました。
」は俗字で、JIS83の「拐」の方が伝統的字体なので、「伝統的字体」に直された文字に移します。これにともない、「一部の表外字が略字体で例示され」を、「一部の表外字が略字体・俗字体で例示され」と改めました。
(Aug16 1998)
- 「表試案」に載っていない文字の例としてあげた「迪」は、人名漢字表にはいっており、常用漢字表表外字試案の範囲外だったので削除しました。
- 常用漢字で増加した字のうち、78JISに伝統的字体が示されているものとしてあげたうち、「瘉」は間違いだったので、「癒」になおしました。
- 「78JISでは一部の表外字が略字体で例示され、83年以降の改訂で伝統的字体になおされた」として例示した文字のうち、78JISの第四刷の正誤表でなおされた文字が含まれていたので、「78JISでは一部の表外字が略字体で例示され、同規格表の第四刷および 83年以降の改訂で伝統的字体になおされた」としました。
(Jul30 1998)
JCS委員会の芝野委員長は、
JIS漢字の規格はISOに国際登録されていますが、文字を割り当てていない空きエリアについては「shall not be used」(使用禁止)と書いてあります。国際的に日本はそう約束したのです。ところが国内規格の解説では「符号表上の予備」とかいって、ここは外字を使ってもいいエリアだと書いてしまいました。国際的には、これは使いませんと約束しながら、国内では相反することをしたわけです。(「朝日総研リポート」1998年2月号)
と発言してこられてきたのですが。新拡張JISは、当初、五千字拡張とアナウンスされていましたが、いろいろな事情で、少なくなるようです。
いくら包摂しても、四千数百字増やしただけでは、現代日本語を完全にカバーするのは無理で、外字は認めざるをえないということでしょうか。というわけで、「文字化けの嵐という悪夢」の外字が原則禁止となったという記述は訂正しました。(Jul02 1998)
来年(1998年)中に出るという Win98日本語版では、外字使用が禁止されると推測しますが(確認したわけではありません)、Win98への移行がすみやかにおこなわれることはないでしょう。新しい OSにはバグがつきものですし、再学習も必要なので、Win95が登場した際は、多くの企業では移行を見合わせ、Win3.1を使いつづけています(Win95の登場から二年たっている現在でも、Win3.1を使っている企業はすくなくありません)。
MSKKはJISなんて相手にしていないんですね。しかし、どうなるんでしょう? (May27 1998)
というわけで、ずっと継子あつかいだった補助漢字JIS X 0212は、一度も日の目を見ないまま、消えてゆきそうな雲行きですが、一度、公的規格となった文字コードはしぶとく生き延びるのが常です。補助漢字の場合、文字コード JIS X 0212として使われることはないでしょうが、Unicodeの一部のCJK統合漢字にはいっているので、文字セットとしての補助漢字は、Unicodeの普及にともない、今後、広く使われるようになるかもしれません。
1997年3月の時点ではこれでよかったと思いますが、Windows98の標準文字セットに補助漢字がはいることが確定的となったようなので、記述を変更しました。
なお、Windows98の文字セットの問題点については、近々、新しいページをつくる予定です。(Feb17 1998)
旧版のブラウザをお使いの方は、表示が不自然になりますが、なにとぞご理解ください。(Oct27 1997)